





集Python、C++、R为一体!编程语言 Julia 1.0 正式发布
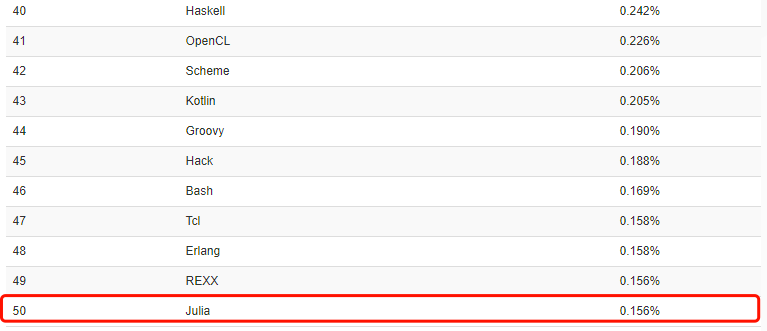
近年来,Julia 语言已然成为编程界的新宠,今年 TOIBE8 月份编程语言排行榜上,Julia 已迅速攀升至第 50 名。短短几年,这门由 MIT CSAIL 实验室开发的编程语言就变得炙手可热,很大部分是因为这门语言结合了 C 语言的速度、Ruby 的灵活、Python 的通用性,以及其他各种语言的优势于一身,并且具有开源、简单易掌握的特点。
8 日,Julia 正式发布 1.0 版本。Julia 团队表示:“Julia 1.0 版本是我们为如饥似渴的程序员构建一种全新语言数十年来工作成果的巅峰。”那么问题来了,Julia 真有这么神?你做好学习一门新编程语言的准备了吗?
为什么你应该学习 Julia?
从 2012 年到现在,Julia 1.0 在编程界已经打出了自己的一片“小天地”。截至发稿前,Julia 在 Github 上已经获得了 12293 颗星星,TOIBE8 月份编程语言排行榜上已迅速攀升至第 50 名。
Julia 之所以这么受欢迎,这与它解决了工程师们一个“坑爹”问题有关:工程师们为了在数据分析中获得速度和易用性,不得不首先用一种语言编码,然后用另一种语言重写,即很多人口中的“双语言问题”。
与其他语言相比,Julia 易于使用,大幅减少了需要写的代码行数;并且能够很容易地部署于云容器,有更多的工具包和库,并且结合了多种语言的优势。据 Julia Computing 的宣传,在七项基础算法的测试中,Julia 比 Python 快 20 倍,比 R 快 100 倍,比 Matlab 快 93 倍。
目前 Julia 的应用范围已经非常广泛了,可以用于天文图像分析、自动驾驶汽车、机器人和 3D 打印机、精准医疗、增强现实、基因组学和风险管理等领域。
两年前,诺贝尔经济学奖得主 Thomas Sargent 和澳大利亚国立大学的经济学教授 John Stachurski,共同建议纽约联邦储备银行把其用于市场走势预测和政策分析的“动态随机一般均衡模型(DSGE)”转到 Julia 语言平台。在项目第一阶段后,他们发现,Julia 把模型运行时间缩短至原先 Matlab 代码的十分之一到四分之三。
除了语言本身的优点,Julia 还拥有非常强大的生态系统,主要应用于数据可视化、通用计算、数据科学、机器学习、科学领域、并行计算六大领域。
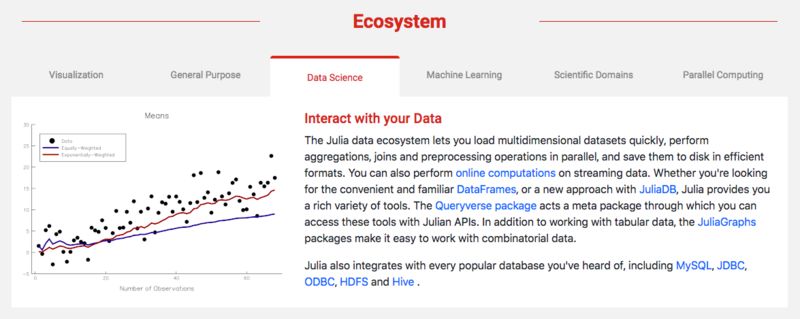
 Julia 在规模化机器学习领域为深度学习、机器学习和 AI 提供了强大的工具(Flux 和 Knet)。Julia 的数学语法使其成为表达算法的理想方式,支持构建具有自动差异的可训练模型,支持 GPU 加速和处理数 TB 的数据。Julia 丰富的机器学习生态系统还提供监督学习算法(如回归、决策树)、无监督学习算法(如聚类)、贝叶斯网络和马尔可夫链蒙特卡罗包等。
Julia 在规模化机器学习领域为深度学习、机器学习和 AI 提供了强大的工具(Flux 和 Knet)。Julia 的数学语法使其成为表达算法的理想方式,支持构建具有自动差异的可训练模型,支持 GPU 加速和处理数 TB 的数据。Julia 丰富的机器学习生态系统还提供监督学习算法(如回归、决策树)、无监督学习算法(如聚类)、贝叶斯网络和马尔可夫链蒙特卡罗包等。
Julia 目前下载量已经达到了 200 万次,Julia 社区开发了超过 1900 多个扩展包。这些扩展包包含各种各样的数学库、数学运算工具和用于通用计算的库。除此之外,Julia 语言还可以轻松使用 Python、R、C/C++ 和 Java 中的库,这极大地扩展了 Julia 语言的使用范围。
所以说,Julia 火起来不是没有原因的,而最新发布的 1.0 版本又添加了很多新功能。
按例,先贴上新版本相关链接:
Julia 1.0 试用版链接:
https://julialang.org/downloads/
GitHub 地址:https://github.com/JuliaLang/julia
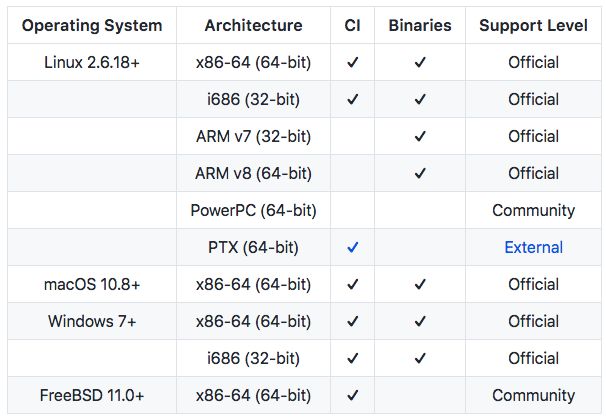
目前支持 Julia 的平台:
Julia 到底是怎样一门语言?
Julia 首次公开面世时便体现出该社区对语言的一些强烈要求:
我们想要一种拥有自由许可的开源语言。我们想要它拥有 C 的速度与 Ruby 的灵活。它要容易理解,像 Lisp 一样真正地支持宏,但也要有像 Matlab 一样的明显、熟悉的数学符号。它还要像 Python 一样可用于通用编程,像 R 一样易于统计,像 Perl 一样可自然地用于字符串处理,像 Matlab 一样擅长线性代数,像 shell 一样擅长将程序粘合在一起。总之,它既要简单易学,但也要让最严肃的黑客开心。我们既希望它是交互式,也希望它是可编译的。
现在,一个充满活力和蓬勃发展的社区围绕着这种语言成长起来,来自世界各地的人们在追求这一目标的过程中不断地精炼并重塑着 Julia。超过 700 人为 Julia 做出了贡献,还有很多人制作了数以千计的令人惊叹的开源 Julia 软件包。总而言之,我们建立的语言:
- 快速:Julia 就是为高性能而设计的。Julia 程序通过 LLVM 编译为多个平台的高效本机代码。
- 通用:它使用多个调度作为范例,使得它很容易表达众多面向对象和函数编程的模式。它的标准库提供异步 I / O、进程控制、日志记录、概要分析、软件包管理器等。
- 动态:Julia 是动态类型的,就像一种脚本语言,并且很好地支持交互式使用。
- 技术:它擅长于数值计算,其语法非常适合数学,支持的数字数据类型众多,并具有开箱即用并行性。Julia 的多次调度非常适合定义数字和数组类型的数据类型。
- (可选)键入:Julia 具有丰富的描述性数据类型语言,类型声明可用于阐明和巩固程序。
- 可组合:Julia 的软件包可以很好地协同工作。单位数量矩阵,货币和颜色数据表都可以进行,并且性能良好。
如果你要从 Julia 0.6 或更早版本升级代码,我们建议首先使用过渡版 0.7,其中包括弃用警告帮助指导完成升级。如果你的代码没有警告,则可以更改为 1.0 而无需任何功能更改。已注册的软件包正在使用该过渡版本发布 1.0 兼容的更新。
1.0 更新了哪些功能?
当然,Julia 1.0 中最重要的一个新功能是对语言 API 稳定性的承诺:你为 Julia 1.0 编写的代码可以继续在 Julia 1.1、1.2 等版本中运行。该语言是“已完善”的,核心语言开发人员和社区都可以放心使用基于此版本的软件包、工具和新功能。
但 Julia 1.0 更新的不仅是稳定性,它还引入了一些强大、创新的语言功能。自 0.6 版以来,新发布的一些功能包括:
- 全新的内置软件包管理器性能得以大幅改进,使安装包及其 dependencies 项变得前所未有的简单。它还支持每个项目的包环境,并记录工作应用程序的确切状态,以便与他人和你自己进行共享。最后,新的设计还引入了对私有包和包存储库的无缝支持。你可以使用与开源软件包生态系统相同的工具来安装和管理私有软件包。JuliaCon 上展示了新功能设计的详细情况:https://www.youtube.com/watch?v=GBi__3nF-rM
- Julia 有了一个新的规范表示缺失值(https://julialang.org/blog/2018/06/missing)。能够表示和处理缺失的数据是统计和数据科学的基础。与 Julian 的一贯风格相符,这个新的解决方案具有通用性、可组合性和高性能。任何泛型集合类型都可以通过让元素包含 missing 的预定义值来有效地支持缺失值。在以前的 Julia 版本中,这种“联合类型”集合的性能会太慢,但编译器的改进现在使得 Julia 可以跟上其他系统中自定义 C 或 C ++ 缺失数据表示的速度,同时也更加通用和灵活。
- 内置的 String 类型现在可以安全地保存任意数据。你的程序数小时甚至数天的工作不再会因为一些无效 Unicode 杂乱字节而失败。保留所有字符串数据,同时标记哪些字符有效或无效,可以使你的应用程序安全方便地处理不可避免具有缺陷的真实数据。
- 语法简单的广播(Broadcasting)已经成为核心语言功能,现在它比以往任何时候功能都更强大。在 Julia 1.0 中,将广播扩展到自定义类型并在 GPU 和其他矢量化硬件上实现高效优化计算变得更简单,为将来提高性能提升铺平了道路。
- 命名元组是一种新的语言特性,它使得通过名称表示和访问数据变得高效快捷。例如,你可以将一行数据表示为 row =(name =“Julia”,version = v“1.0.0”,releases = 8),并将版本列作为 row.version 访问,其性能与不甚快捷的 row [2] 相同。
- 点运算符现在可以重载,让类型使用 obj.property 语法来获取和设置结构字段之外的含义。这对于使用 Python 和 Java 等基于类的语言更顺畅地进行互操作是个福音。属性访问器重载还允许获取一列数据以匹配命名元组语法的语法:你可以编写 table.version 来访问表的 version 列,就像 row.version 访问单行的 version 字段一样。
- Julia 的优化器在很多方面变得比我们在这里提到的更聪明,但有一些亮点值得一提。优化器现在可以通过函数调用传播常量,可以更好地做到死码消除和静态评估。另外,编译器在避免在长生命周期对象周围分配短期包装器方面也要好得多,这使得程序员可以使用便利的高级抽象而无需降低性能成本。
- 现在使用声明相同的语法调用参数类型构造函数。这消除了语言语法的模糊和令人困惑的地方。
- 迭代协议已经完全重新设计,以便更容易实现多种迭代。现在是一对一定义一个或两个参数方法,而不是定义三个不同泛型函数的方法——start,next,和 done。这通常使得使用具有开始状态的默认值的单个定义可以更方便地定义迭代。更重要的是,一旦发现无法生成值就可以部署迭代器。这些迭代器在 I / O、网络和生产者 / 消费者模式中无处不在;Julia 现在可以用简单直接的方式表达这些迭代器。
- 范围规则简化。无论名称的全局绑定是否已存在,引入本地范围的构造现在都是一致的。这消除了先前存在的“软 / 硬范围”区别,并且意味着现在 Julia 可以始终静态地确定变量是本地的还是全局的。
- 语言本身非常精简,许多组件被拆分为“标准库”软件包,这些软件包随 Julia 一起提供但不属于“基础”语言。如果你需要它们,它可以给你方便(不需要安装),但不会被强加给你。在未来,这也将允许标准库独立于 Julia 本身进行版本控制和升级,从而允许它们以更快的速度发展和改进。
- 我们对 Julia 的所有 API 进行了彻底的审查,以提高一致性和可用性。许多模糊的遗留名称和低效的编程模式已被重命名或重构,以更优雅地匹配 Julia 的功能。这促使使用集合更加一致和连贯,以确保参数排序遵循整个语言的一致标准,并在适当的时候将(现在更快)关键字参数合并到 API 中。
- 围绕 Julia 1.0 新功能的新外部包正在构建中。例如:
- 正在改进数据处理和操纵生态系统,以利用新的缺失支持
- Cassette.jl(https://github.com/jrevels/Cassette.jl)提供了一种强大的机制,可以将代码转换传递注入 Julia 的编译器,从而实现事后分析和现有代码的扩展。除了用于分析和调试等程序员的工具之外,甚至可以实现机器学习任务的自动区分。
- 异构体系结构支持得到了极大的改进,并且与 Julia 编译器的内部结构进一步分离。英特尔 KNL 只能用 Julia 工作。Nvidia GPU 使用 CUDANative.jl(https://github.com/JuliaGPU/CUDAnative.jl)软件包进行编程,Google TPU 的端口正在开发中。
另外,Julia 1.0 还有无数其他大大小小的改进。有关更改的完整列表,请参阅文件:https://docs.julialang.org/en/release-0.7/NEWS/。
在 2012 年的文章《为什么我们创造 Julia》这篇博客文章中(https://julialang.org/blog/2012/02/why-we-created-julia),我们写道:
它不完整,但现在是 1.0 发布的时候——我们创建的语言叫做 Julia。
现在,我们提前叩响了 1.0 版本发布的扳机,但它发布的时刻已然到来。真诚地为这些年来为这门现代化编程语言做出贡献的人们感到骄傲。
查看英文原文:https://julialang.org/blog/2018/08/one-point-zero
本文文字及图片出自 InfoQ
你也许感兴趣的:
- 世界末日的最佳编程语言
- 编程语言的选择
- Julia 的新天地
- 【程序员搞笑图片】数据类型简明指导
- 33 种编程语言的 UUIDv7 实现
- 【外评】Rust,你错了
- 【外评】为什么人们对 Go 1.23 的迭代器设计感到愤怒?
- 华为自研编程语言“仓颉”来了!鸿蒙应用开发新语言,性能优于 Java、Go、Swift
- 【外评】JavaScript 变得很好
- 【外评】华为发布自己的编程语言 “仓颉”











你对本文的反应是: