





如何解决看起来不可能的工程问题?
Scalyr是一个基于云的服务器日志监控工具。其官方博客曾发表过一篇文章,描述如何使用蛮力方法实现数十GB日志数据的秒级查询。在对所有日志进行实时探索性分析时,那是个行之有效的方法,但无法实现Scalyr某些功能(如仪表板、预警)所需要的、TB级数据的秒级查询。近日,前谷歌员工、Scalyr创建者Steve Newman撰文介绍了他们如何遵循如下两个原则解决该问题:
- 常用的用户行为对应简单的服务器行为;不常用的用户行为则可以对应复杂的服务器行为。
- 寻找一种可以简化关键操作的数据结构。
Steve指出,重定义可以让一个看似不可能的挑战变得容易处理,而这两个原则有助于寻找一种合适的重定义方法。
“不可能”的问题
Scalyr提供了许多服务器监控和分析工具。为了支撑这些工具,他们将每项功能都实现为一个通用数据集上的一组查询。有些功能需要多个查询。例如,仪表板可以包含任意数量的图表,每个图表又包含多条曲线,而每条曲线对应一个复杂的日志查询。假如一个自定义的仪表板容包含十二个图表,每个图表4条曲线,用户选择了一个时间跨度为一周的仪表板视图,而他们每天生成的日志量为50GB,那么,就需要在350GB的数据上执行48个查询。没有哪个蛮力算法可以在零点几秒内提供查询结果。同样,预警功能也会产生大量的查询。Scalyr的日志预警可以触发非常复杂的条件,比如,过去10分钟内99%的Web前端响应时间超过800毫秒。单个用户可能有成百上千的预警,它们每分钟就需要计算一次。而通常,预警查询对延迟很敏感,需要在几毫秒内响应。
重定义问题
综上所述,仪表板和预警都会产生大量的查询,但都不能接受太长的查询执行时间。所幸,它们有一个共同点:查询事先已知,查询很常用,而新查询很少。按照上文提出的原则,他们需要一种可以简化仪表板和预警查询的数据结构,哪怕创建查询变得复杂也可以接受。
Scalyr支持多种输出结果,包括文本、数值、直方图和键/值数据。不过,仪表板和预警查询总是生成一个数组。每个查询定义了一个时间上的数值函数,可能是“每秒产生的错误信息”、“服务器X上的空闲磁盘空间”等。执行查询就意味着使用函数求值,计算结果为数值序列,每个数值对应一个特定的时间区间。
他们通过预计算来简化函数求值过程。他们采用的数据结构非常简单:每个查询对应一个数组。查询每隔30秒执行一次,并输出一个数值。他们将那个数组称为“时间序列(timeseries)”。例如,用户仪表板上有一张图表,上面显示了Web服务器池产生5xx错误的速率。为此,他们创建了一个时间序列,每30秒记录一个错误数:

这样,他们就可以快速生成任意时段的图表(为了生成更长时段的图表,他们还以逐步增大的时间间隔存储一些冗余数组)。
时间序列维护
当有日志消息到达时,他们需要对每个相关时间序列进行增量更新。例如,如果一个新的Web访问消息包含有介于500-599之间的状态码,那么他们就需要增加对应特定时间间隔的“5xx错误”时间序列的计数器。这里有个问题,就是针对一个新消息,如何确定哪些时间序列需要更新。由于仪表板和预警查询通常使用相同的字段进行过滤,如主机名、指标名,所以他们使用这些字段构建了一棵决策树,通过它快速确定与日志消息匹配的候选时间序列列表。
Steve举了一个例子。假如有十二个时间序列,遵循下面的消息选择标准:
host="frontend1" && metric="memfree" host="frontend1" && metric="diskfree" host="frontend2" && metric="memfree" host="frontend2" && metric=diskfree" host="backend1" && metric=memfree" host="backend1" && metric=diskfree" host="backend2" && metric="memfree" host="backend2" && metric="diskfree" pool="webapp" && status >= 400 && status <= 499 pool="webapp" && status >= 500 && status <= 599 pool="api" && status >= 400 && status <= 499 pool="api" && status >= 500 && status <= 599
这些时间序列可以组织成下面这样一棵决策树:
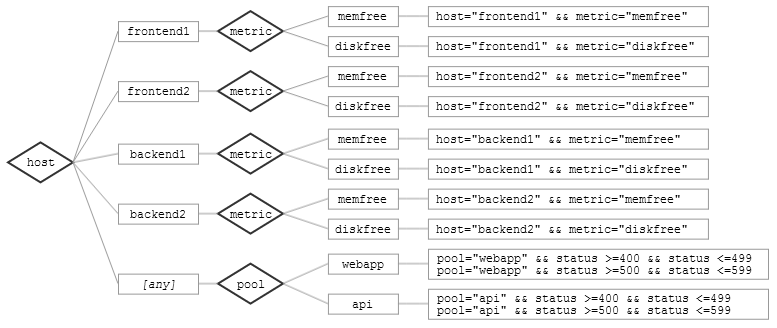
如果收到了下面这样一条消息:
host=frontend1 metric=memfree value=194207
则该消息会从决策树的根节点开始匹配,首先会进入 host=“frontend1”和host=[any]节点。从host=“frontend1”向下,可以进入metric=“memfree”节点,并匹配到该节点下的时间序列(host="frontend1" && metric="memfree");从host=[any]节点向下,未能找到匹配的分支,不再向下匹配。就是说,在这种情况下,只需要检查时间序列host="frontend1" && metric="memfree"是否需要更新。而对于消息host=frontend1, metric=memfree, pool=webapp,则需要检查3个时间序列。
决策树生成算法
决策树生成采用了一个简单的贪婪算法:
- 找出所有用于
==检验并在至少一个时间序列中出现的字段名(比如,上例子中的host、metric和pool)。 - 根据每个字段名划分时间序列。如果一个时间序列无法匹配该字段值域中的某个值,那么就将其划分到[any]组。计算每个组中时间序列的数量,并找出最大的组。在上例中,host字段产生了4个大小为2的组和一个大小为4的组([any]组)。因此,最大组的大小为4。
- 创建一棵树,其根字段要能够使最大组最小化。在上例中,如果以host和metric字段为根节点,则最大组的大小均为4;如果以pool字段为根节点,则最大组为[any],大小为8。因此,可以使用host和metric的其中一个作为根节点,而不使用pool。
- 在每棵子树上递归执行步骤3。
在Steve举的一个例子中,与蛮力算法相比,该算法带来了33倍的性能提升。在实际的生产环境中,它对性能的提升更明显。
本文文字及图片出自 InfoQ
你也许感兴趣的:
- Let’s Encrypt:准备开始签发IP地址证书
- 谷歌浏览器将提供内置翻译和语言检测 API
- OpenAI 将用 Rust 重建 Codex CLI,放弃之前的 TypeScript 版本
- 用 AI 生成的安卓 App:优点、缺点与令人震惊之处
- 为什么所有浏览器的用户代理(User-Agent)都以“Mozilla/”开头?
- 新发现的 Linux udisks 漏洞使攻击者能够在主要 Linux 发行版上获得 root 权限
- 没错,没人关心 Linux 上的使用友好性
- Git Notes:Git 最酷但最不受欢迎的功能
- Kubernetes 2.0 将会是什么样子
- bzip2 crate 从 C 切换到 100% rust










你对本文的反应是: