



我们每个人都知道是个不好的做法,但有时我们还是要这样做:我们执行SELECT * 语句。这个方法有很多弊端:
- 你从你的表里返回每个列,甚至后期加的列。想下如果你的查询里将来加上了VARCHAR(MAX)会发生什么……
- 对于指定的查询,你不能定义覆盖非聚集索引来克服执行计划里的查找(lookup)运算符,因为你会在额外的索引里重复你的数据……
现在的问题是你如何阻止SELECT *语句?当然你可以进行代码审核,你可以提供最佳模式指导,但谁最终会留意这些?基本上没有人——很遗憾这就就是令人伤心的事实……
但有一个非常简单方法来阻止SELECT *语句,在表里用技术层面来解决。
这个问题的解决方法非常简单:在你的表定义上增加一个产生除零错误的的计算列。这个方法超简单,但却真正有效。我们来看下面的表定义:
-- Create a simple table with a computed column that generates
-- a divide by zero exception.
CREATE TABLE Foo
(
Col1 INT IDENTITY(1, 1) NOT NULL PRIMARY KEY,
Col2 CHAR(100) NOT NULL,
Col3 CHAR(100) NOT NULL,
DevelopersPain AS (1 / 0)
)
GO
-- Insert some test data
INSERT INTO Foo VALUES ('a', 'a'), ('b', 'b'), ('c', 'c')
GO
如你所见,我这里增加了一个进行除零的计算列。这表示当是查询这个列时,你会得到一个错误信息——例如在SELECT * 语句里:
1 -- A SELECT * statement doesn't work anymore, ouch... 2 SELECT * FROM Foo 3 GO
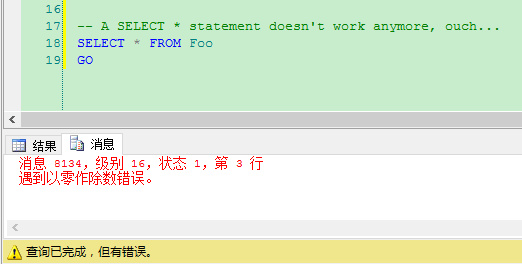
但另一方面如果你通过名称指定查询列,你不会反悔计算列,你的查询如愿正常执行:
1 -- This SQL statement works 2 SELECT Col1, Col2, Col3 FROM Foo 3 GO

很不错吧,是不是?
小结
在各个交流会上我经常提到:有时我们只是变得太复杂了!这个用计算列的方法非常简单——肯定需要表架构修改。但下次设计新表的时候,要记得用这个方法。
本文文字及图片出自 博客园












你的反应是: