2015 Hadoop峰会:世界沉醉在数据里
Hortonwork、Cloudera、SAP、IBM、惠普、雅虎等25+数据服务技术提供商,Schlumberger、verizon、迪斯尼、Airbnb、赛门铁克、Aetna等各行各业的领军企业,Hadoop威风仍在。

2015年6月9-11日,我在美国加州硅谷参加了第八届全球Hadoop技术峰会(Hadoop Summit 2015)。在短短的3天时间里我既见识到了Hortonwork、Cloudera、SAP、IBM、惠普、雅虎等25+数据服务技术提供商围绕大数据设计开发的产品,也聆听了Schlumberger(能源巨头)、verizon(通信巨头)、迪斯尼(娱乐巨头)、Airbnb(共享经济代表企业)、赛门铁克(信息安全巨头)、Aetna(医疗保险巨头)这些各行各业的领军企业用数据产品为公司创造价值的真实案例。我最大的感受就是有这么多的公司相信数据的价值,并且真真切切地将数据作为企业的重要资产来维护和使用。简单地用峰会一位嘉宾,微软分管数据平台副总裁Ranga的语言总结--“世界沉醉在数据里” (The world is drunk on data)

Fig 1:第八届全球Hadoop技术峰会(Hadoop Summit 2015)会场掠影
什么是Hadoop?
自从我发了出席Hadoop技术峰会的朋友圈以后,就被小伙伴们各种“酷炫”“有用”的评论刷屏了。不过遇到了一个难点:如何向我妈解释“什么是Hadoop”这个问题。这个问题大概有点像向程序员解释CL的红底鞋到底好在哪一样难。作为一个接触了Hadoop一年的技术新人,我也还在摸索的道路上,不过幸好我们有亲爱的维基百科,在上面,Hadoop的定义是:一个用java语言编写的便于大型数据集合的分布式储存和计算的软件框架。简单来说,这是计算机领域的一个开源软件,任何程序开发者都可以看到它的源代码,并且进行编译。它的出现让大数据的储存和处理一下子变的快了很多,也便宜了很多。
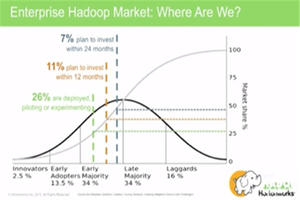
Fig 2:Hadoop Summit 2015主题演讲中Hortonwork CEO Rob介绍Hadoop技术在企业级应用中所占的市场份额
Hadoop是怎么做到将大数据储存和处理变得又快又便宜的?
这个讲起来可以讲三天三夜呢。不过举个简单的例子,现在需要数一个图书馆有多少本书,一个人数肯定很慢,需要很多个人数,而且最好每一个区域的书都有2-3个人数一遍,这样统计的数量才比较准确。所以就需要有一个机制将书籍分好区,规定每一个人负责数哪几个区的书,这样即使有人生病了也不会影响到总体统计工作的完成。这里的人就是Hadoop所操控的一台台个人计算机,机制就是Hadoop的核心MapReduce方法。在我看来,Hadoop的分布式计算功能就像一个精明的资本家设计的工作分配制度,既保证工作的完成不会特别依赖某一个人,又保证了如果工作量上升了只需要再雇一个劳工就能解决问题。

Fig 3:Hadoop Summit 2015微软数据平台副总裁Ranga主题演讲截图,展示零售业,医疗,支付,教育,机器维护和交通领域基于Hadoop技术的数据红利(Data Dividend)
什么是Hadoop技术峰会(Hadoop Summit 2015)?
要解释这个问题就要先解释一下Hadoop对于企业的重要性。ForresterResearch(一家著名的咨询公司)的首席分析师Mike Gualtieri在峰会中预测,100%的大企业已经或将在未来2-3年内开始使用Hadoop。不管你是能源,通信,医疗,娱乐,生产制造,互联网行业的企业,你的数据总是会越来越多,而如果需要从这些海量数据中挖掘出价值,提高企业的整体竞争力,你就需要一个强大的储存和处理数据的能力,Hadoop及其泛生态圈就能帮你实现!(真的不是在打广告。。)Hadoop技术峰会就是Hadoop的开发者和使用者交流的地方。峰会为期三天,期间有160多场讲座,有来自Aetna, Facebook,谷歌,微软,迪士尼,Airbnb等公司的各路技术大拿分享他们关于开发使用Hadoop的故事。通过讲座,自由讨论,聚餐,party等形式参会者会与来自39个国家的4000+的参会者进行沟通。某种意义上来说,Hadoop Summit就像是个宗教活动,虔诚的数据爱好者相聚在一起,看看你在做什么我在做什么,共同讨论关于数据的信仰。

Fig 4:Hadoop Summit 2015第一天下午讲座日程截图
技术新人如何最大化一场技术峰会的收获?
参加某一行业的峰会最重要的当然是了解行业趋势,都有哪些新的概念,这样慢慢得你才说得出内行话。这也是为了平常工作做准备,比如我,去年参加过InfoQ组织的QCon(全球架构师大会),大会内容大概听懂了30%,经过一年的工作学习和查字典(wiki),这次参加Hadoop峰会我大概能听懂50%,和同行交流的时候总算还能一句搭一句地深入讨论。
当然能问出好的问题也是峰会收益最大化的有效手段。我的兴趣主要在产品方面,所以主要听的是Hadoop技术在不同公司里的usecase(使用场景),同时我也总结了一下技术新人应该如何玩转这一类型的技术峰会的经验,特此分享:
- 新的概念
- 围绕Hadoop的生态系统
- 人
这些是我觉得作为一个掌握的知识还不够全面的技术新人在峰会上应该多投入的地方:看看行业里都有哪些新的概念,补充一下自己的专业字典;了解围绕某个技术的上下游提供商的发展情况,谁在开发什么样的软件,谁在为什么样的软件埋单,这有助于技术新人在参与设计产品的时候有个全局的概念;最后最重要也是最容易实现的,就是联络参会的人。大家都是付了昂贵的门票($900+)来参加这次峰会的业内人士,所以每个人都像一座金矿,都有自己领域的专业知识,都会遇到相似的问题,开放的交流说不定会让一直困扰你的一个问题找到全新的解法。除此以外,同行的交流也能让你不觉得孤独,很多你想尝试的做法也许能从别的公司的执行数据反馈中找到自信。

Fig 5:Hadoop Summit 2015参会者在白板(Job Posting Board)前查看有关Hadoop技术的岗位:雅虎在招人!苹果在招人!Uber在招人!….左下角我们唯品会美国研发中心也在招资深数据科学家哟!
下面就是我在这三个方面的一些收获:
新的概念
概念一:“大铁遇到大数据”(Big Iron Meets Big Data)
这句话是通用电气负责软件的首席信息官Vince在峰会上提出的,总结的是这个时代大数据与物联网(第一阶段主要在工业物联网)将相辅相成。这从本次参会的公司名单上也能看出一二:医疗,能源,机械,通信这些传统行业纷纷粉墨登场,介绍他们在大数据/互联网方面的尝试。当然从我和参会人的讨论看来,目前这些传统企业的大数据运用还仅限于通过传感器搜集数据然后做数据分析,以后的发展还很长。

Fig 6:Hadoop Summit 2015通用电气首席信息官Vince的主题演讲中提到的关于物联网的惊人数据,Hadoop技术配合物联网将打开无限价值:到2020年为止,世界上有240亿台设备介入物联网,96%的企业领导表明在接下来3年要试水物联网,到2022年为止物联网将达到14.4万亿美金的市场。其中7大主要使用场景是:智能工厂,市场营销,智能电池,游戏娱乐,智能建筑,商用地面交通工具,医疗。
概念二:”世界沉醉在数据里” (The world is drunk on data”)
这个概念与“数据湖’(Data Lake)息息相关。数据湖是个相对年轻的概念,在它之前大家普遍接受的是“数据超市”(Datamart),意指在企业里将数据(水)像瓶装水一样过滤消毒打包好后便于各部门使用。与之相对应的,数据湖就是一个原始数据的聚合地,那些没有经过处理的数据都会被丢到一个容器里,只有当需要用的时候,才从这个数据湖里取用并做处理。这个湖的上下游的流淌是目前软件开发重点投资的地方。类似的概念还有“数据沼泽”。
其他频繁被提到的词,欢迎大家自己百科~
Data Governance,Data Lineage,Data Dividend,Data wrangling
围绕Hadoop的生态系统
董飞在他的文章后Hadoop时代的大数据架构中详细介绍了围绕Hadoop的生态系统。我的总体感觉就是原来对于这么多(至少30家)企业来说,数据和Hadoop就是他们赖以生产的资源和工具,如果说数据如水的话(参考上一段的“数据湖”概念),我至少看到了有水源勘探的公司,钻井的公司,打水,教人打水的公司,教人节水的公司,消毒水的公司,还有给水流情况做报表的公司。关键是“打水”和“教人打水”的公司(hortonworks)还上市了呢!
当然还是说点具体的技术,spark是大家热议的一个技术,从会场爆满的情况就可以看出大家的兴趣;Apache Drill是2015年5月发布的一个新的基于Hadoop的开源技术,最早起源于谷歌的dremel系统,它的主要优势是可以让人们实现对于分布式大数据的可交互的实时数据分析;Airbnb也自己研发了一套开源的流程管理平台Airflow,吸引了很多业界关注。

Fig 7:Hadoop Summit 2015迪斯尼数据平台开发资深工程师Caleb介绍著名的魔法手环”Magic Bend”的Hadoop框架
人
这次参会在party的时候认识了Hortonwork和Cloudera的人,总算了解两家是竞争对手关系。在听讲座的时候遇到一个可爱的印度小哥,一家公司为了雇佣他特地送给了他来参加hadoop summit的门票。中午吃饭的时候看我边上一个白头发老爷爷一个人吃饭挺孤单的,就聊了一下,他主要帮助通用电气做引擎系统优化。我们在对数据的处理方面遇到过同样的烦恼。后来回家一查,原来他是一家大数据初创企业的创始人兼首席技术官。像这样的例子非常多。

Fig 8:Hadoop Summit 2015第二天晚上在San Pedro Market有盛大的party活动,所有参会人员凭胸卡就可以参加。在这里不仅有免费的印有hadoop峰会字样的人力三轮车负责接送会场和party的人群,还有现场乐队表演,最棒的是有世界各国的美食和美酒可以品尝。晚风徐徐,竟是醉了。
除此以外,我还参加了“使用Hadoop的女性”(Women in Hadoop)活动,大多数参与的人都是开发使用Hadoop的女性同胞们,确实是Hadoop使用者中的“少数民族”。很经典的一件事就是一场讲座结束后男洗手间门口总是排起了长队,而女洗手间则根本没有这样的烦恼。另一个我们讨论的发现就是在12位主题演讲嘉宾中没有一位女性。但是,在技术讲座中凡是有女性参与的讲座,观众都很多,讲座很有条理,效果也非常好。这就说明并不是女性同胞不适合讲座,只是大家缺乏了解参与讲座的途径,也缺少发表演讲的鼓励。所以Women in Hadoop这个活动的目的就是围绕“女士当自强”为主题讨论一下我们可以做什么样的事帮助更多聪明的女性加入到hadoop技术的大军中。参加活动的还有一些男士,比如迪士尼负责magic bend数据开发的Caleb,他说他有一个女儿虽然很小但是对技术很感兴趣,问我作为年轻的女士有什么好的建议。最后我们通过每人30秒的自我介绍环节互相认识,加了LinkedIn,希望在以后的职业发展道路上能够互帮互助。

Hadoop Summit 2015之”使用Hadoop的女性” Women in Hadoop BOF Session展示的PPT页面之一,引人深思。

本文由 TecHug 分享,英文原文及文中图片来自 zhuanlan.zhihu.com。
你也许感兴趣的:
- 雷蒙德·陈 旧事新说:当愤怒的客户要求与比尔·盖茨通话时
- 微软否认使用人工智能用Rust语言重写Windows 11
- 讨论:为什么Python能胜出?
- 使用 PostgreSQL 18 实现即时数据库克隆
- 我断开IPv4整整一周,只为理解IPv6过渡机制
- 我在地铁上编程
- Debian 的 Git 迁移计划
- Debian将龙芯LoongArch列为官方支持的架构
- Android对美国外部内容链接引入2-4美元安装费及10-20%分成政策
- 软件控制等级军事标准

你对本文的反应是: