计算机中的黑魔法:尾递归
目前是凌晨1点48分。嗯,刚刚写完这篇日志。忍不住想说点什么,或许是当一个不好的书托。可能这些内容对于很多人来说是没有用的,他们甚至会鄙视我写的东西,觉得为这些东西花费时间不值得。对于这些人,我想说,每一个对计算机有着浓厚兴趣的人,都有着一个想够彻头彻尾了解每天超过12小时面对的这台机器是如何工作的愿望

声明:本文是作者在学习SICP有关过程抽象知识的理解,由于书中的语句有些晦涩,所以将作者的理解共享给大家希望帮助一些朋友。原书对尾递归并没有太多介绍,但是这里给出了详细的解释。
目前是凌晨1点48分。嗯,刚刚写完这篇日志。忍不住想说点什么,或许是当一个不好的书托。可能这些内容对于很多人来说是没有用的,他们甚至会鄙视我写的东西,觉得为这些东西花费时间不值得。对于这些人,我想说,每一个对计算机有着浓厚兴趣的人,都有着一个想够彻头彻尾了解每天超过12小时面对的这台机器是如何工作的愿望。像SICP和CSAPP这种书无疑是枯燥的,你可能一天看下来,仔细品读的话只能看三四页,但是如何你能够真正理解这几页书的内涵的话,那么收获将是巨大的。从去年5月份,陈大师推荐我读CSAPP之后,我才真正找到了那种看上去很枯燥,但是一读起来就欲罢不能的书。这类的书读起来都很困难,如果你带着很强的功利性来读的话,是不可能读下去的。我想了想,能够支撑我一天坐在那琢磨这几页书中说的核心意思的力量,就是来源于我真正想了解计算机是怎么工作的,获取这种信息对于我来说是非常快乐的,这种感觉是奇妙的。
函数和计算过程的区别
函数一般是指数学上面的一种计算形式,偏向说明语句,描述如何根据给定的一个或者几个参数去计算出一个值。如SICP中关于求一个数的平方根的函数,我们在该函数的说明中可以推断出关于平方根的一些具体性质和一般性的事实,但是我们无从得知计算一个数的平方根的具体方法。你可能会说,求平方根不就是开根号么。可是你有没有想过,[开根号]也仅仅是一个说明性的语句,具体怎么计算你还是不知道的。延伸到计算机当中的函数,其实和数学上面的函数意义是相同的,我们只不过是换成高级程序设计语言来写我们对于一个函数一般性事实的说明,实际上我们并没有给出一个具体的计算过程。比如求平方根,如果我们是调用math.h中的库函数来求的话:sqrt(x*1.0),这种形式只是一个说明型的语句,我们利用这个语句来指导计算机去计算,但实际上这个函数并没有提供具体的计算过程。计算机当中的解释器就负责把这种说明性语句转化成真正的计算过程(期待到时候写一个解释器哇)。
其实感觉这两者的区别就和写作文一样,一个是提纲,另外一个是具体的内容。
触摸过程的抽象
SICP中关于求一个数平方根的问题,使用的是牛顿的逐步逼近法则,不断的去求新的猜测值,直到结果满足一定的精度结束。求平方根是一个大的功能,想要完成这个大的功能还需要一些小的功能来辅助。
过程抽象的实质就是一种功能的分解
我们把整个一个大的计算过程分为几个部分,每一个部分都能单独完成其中的一个小功能,他们组合起来又能够完成最终的功能。所谓过程的抽象和C++中的面向对象思想是和相像的,没准都是一个东西,我不太确定,但是过程的抽象说的都是一个意思,就是对创造者来说重要的是过程的实现,而对于使用者来说,过程的抽象可以屏蔽掉内部实现的细节,从而减轻使用者的负担,只关心这个过程的『黑盒』能够做什么。所以这样一来就增加了程序局部的可替换性,因为对于实现一个功能来说,过程的内部实现可以多种多样。
抽象1—局部名字
大家都知道调用函数或者过程的时候,有的时候需要传递一些合适的参数,在调用的过程中,函数的形式参数的名字对我们来说其实并不重要,相对于使用者来说确实是这样。但是对于过程的设计者来说,形式参数的名字,或者说是局部变量的名字,对于整个过程能够正常的执行就非常重要了。这也是过程抽象当中的一个细节,计算机把一些复杂的东西封装到了内部。
关于过程的抽象中可能会有两个新的概念,约束变量和自由变量。单就一个过程来讲,我的理解是约束变量就是一种名字是什么无所谓,但是统一换名之后不改变过程意义的一种变量,他有自己的作用域,类比于局部变量吧。而自由变量就类比于全局变量,或者静态变量,我是这么理解的。约束变量的名字并不重要,重要的是哪些地方用了同一个约束变量。
为什么说约束变量的名字对于过程的执行是非常重要的呢。很直接的一个理解就是:局部变量可以在作用域内可以屏蔽同名的全局变量,类比一下,约束变量在相应的作用域内会屏蔽同名的自由变量。
(define (good-enough? guess x)
((abs (- (square guess) x)) 0.001))
举例来讲,在上面这个过程中,guess 和 x 是good-enough?这个过程的两个约束变量,<, abs, -, square都是自由变量。自由变量是和环境相关的,他们已经有了确定的意义来保持他们正常的执行,但是如果现在guess这个约束变量改名为abs,将会导致abs这个自由变量的意义被约束变量屏蔽,过程中出现的abs为约束变量,不在具有自由变量当中求绝对值的功能。
所以说,对于过程的设计者而言,过程实现中,自由变量和约束变量的名字都在哪些地方用到是一个非常需要注意的地方,一个过程的顺利执行依赖于约束变量和自由变量的名字不同,并且自由变量的意义正确。
抽象2—内部定义和块结构
这一点的抽象就更加为我们过程的使用者考虑,它也是一种局部的概念,像局部变量一样,只有内部的作用域可以访问并且识别他,作用域之外是不知道作用域内有这个东西的。只不过我们之前抽象的是变量,这次抽象的是过程。
sicp中的求平方根的过程,和用户交互的仅仅是一个接口sqrt,其中的子过程的具体实现细节都被抽象一个个的【黑箱】。但是对于用户来说,这些实现计算过程的黑箱是没有用的,只会扰乱他们的思维,并且在用户想自定义一个与这些黑箱中的某一个同名的过程的时候是不被允许的(不能在一个作用域内定义两个同名的过程),这些有着具体功能的【黑箱】污染了全局名字环境。
对于一个结构局部的东西,我们更好的方式是把他们定义在这个结构的内部,而不应该放在全局环境范围内,因为你需要的并不是其他人也需要的,如果其他人不需要这些东西,那么他们的命名就有可能造成过程调用的命名冲突,造成程序混乱。
scheme支持在过程的内部再定义新的过程,内部新定义的过程只能在内部作用域可见,外部是不知道有内部这些过程的定义的。
(define (sqrt x)
(define (good-enough? guess x)
(abs (- (square guess) x)) 0.001))
(define (improve guess x)
(average guess (/ x guess)))
(define (sqrt-iter guess x)
(if (good-enough? guess x) guess
(sqrt-iter (improve guess x) x)))
(sqrt-iter 1.0 x))
根据上面的例子来看,我们就把求平方根这计算过程中用到的小黑箱一个一个的都定义在了这个过程的内部 ,过程之外看不到他们,这种嵌套的过程定义就叫做块结构。局部化使程序更清晰,减少全局名字,减少相互干扰。除此之外,由于将一些黑箱进行了内部定义之后,还有一处可以改进的地方,就是参数x的使用。由于局部过程的形参都在x的作用域内,我们就不必在局部过程中再传递x了,直接调用即可。相对于局部过程来说,现在的X由原来的约束变量,变为现在的自由变量了。
计算过程的多重形态
我们可以用不同种类的过程来完成同一件任务,那么在真正的程序设计的时候,我们应该选用哪种方式呢?按照之前数据结构的角度来看,我们有两个指标:时间复杂度和空间复杂度。不同的过程自然有这不同的计算过程,我们应该通过衡量两个不同计算过程的上述的两个指标来确定最终选择哪一个作为最终版本。这就要求我们能够准确的观察到任何一个过程执行的过程和执行的效果,以及执行过程中所耗费的各种资源。
递归和迭代应该是两种非常重要的计算形式。如果一个问题同时可以用这样两种形式解决,那么我们应该选择哪一种呢?
在以实例说明递归和迭代的区别之前,首先要明确这样两个概念的区别:
递归计算进程:是计算中的情况和具体的执行行为,反映计算中需要耗费资源维持的过程执行的某些信息和情况。 用递归方式定义过程:是程序写法,在定义过程的代码里出现了对这个过程本身的调用,但是实际的计算过程可能并不需要耗费资源来进行维持过程的执行情况。
假如现在有一个求n的阶乘的需求:我们有正向和逆向两种思路来求得结果
反向(线性递归)
算法如下:n! = n (n-1)! = n (n-1) (n-2)!…..2 1 = n * (n-1)!
有了具体的计算进程,我们可以根据它来写一个过程
(define (factorial n)
(if (= n 1)
1
(* n (factorial (- n 1)))))
PS:可以看出这个过程在定义的时候调用了自身
假设现在我们想计算(factorial 6),根据shceme的代换模型推导,可以得出如下计算进程图示:

从图示中我们可以看出,当我们计算(factorial 6)的时候,根据计算过程的定义,要执行(* 6 (factorial (- 6 1)))。通过这一个复合的表达式我们就可以看出来,(factorial 6)这一步的计算结果并没有计算出来,它需要计算下一个状态来辅助它得出(factorial 6)这一步的计算结果。因为本次的计算没有完成要进行其他的运算来辅助完成,那么本次的运算就算是中断了,既然中断了,我们就需要保存现场,保存此次计算过程目前的状态(变量等等一些资源)以便当下一状态的计算结果出来之后能够顺利的衔接上,从而计算出最终的结果。以后的计算进程仍然是按照这种形式来的,直到遇到边界。
到此为止,我们就知道,这个计算进程是一个递归计算进程,因为他在计算的进程当中需要耗费资源来保存所需的一些情况和信息。递归的计算过程,想必大家都很熟悉,它是属于一种推迟求值的方式,不能够立即求出最终结果,每一次的计算都依赖于它的子计算状态,直到遇到边界之后,才逐层返回计算结果,最终返回到起点,求出结果。可以说,递归是从后向前推的过程,计算最后一步,也就是最终结果,也许就会需要倒数第一步的结果,那么就计算倒数第一步,以此类推,直到计算到第一步的时候,利用题设条件可以得到第一步的最终结果,然后再把计算结果逐层返回到起点,也就是计算最后一步的位置,得到最终结果。(是深度优先搜索的道理)但是如果计算的次数太多,迭代的层数太深,留给过程的栈空间很有可能会溢出,造成爆栈。
那么,根据上面的时间和空间复杂度两个指标,我们将评判这个用递归计算阶乘的计算进程的好坏。(其实计算进程就是算法,有木有?!)
我们可以看到,如果n是6,那么一共要计算12次,如果n是5那么要计算10次,所以相应的时间复杂度大致可以估算为O(N)。从(factorial 6)递归到边界最低端的时候,一共进行了6次迭代,随着n的增加,递归的次数会随n线性增长,所需的内存空间也会线性增长。所以控件复杂度应为O(N)。
综上所述,整个递归计算进程已经评价完毕,准确的说,这是一个线性递归计算进程。
正向(线性迭代)
算法:n!就是从1开始一直累乘到n,最终的累乘结果等于n!
根据这个算法,写出一个过程如下
(define (factorial n)
(fact-iter 1 1 n))
(define (fact-iter product counter max-count)
(if ( counter max-count) product
(fact-iter (* counter product) (+ counter 1)
max-count)))
从上述的过程我们可以看出,它在定义的时候,也是调用了自身。计算(factorial 6)的进算进程图示如下:
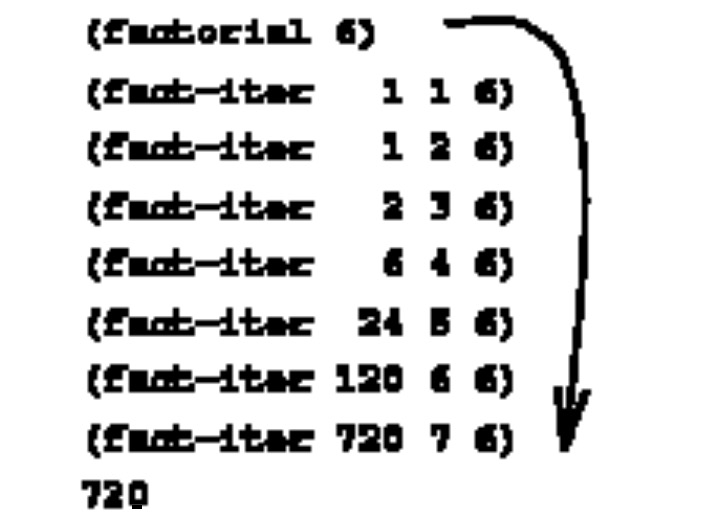
根据图示可以看出,每一次的计算状态由三个变量来维持,而且每一个状态的计算和其他状态的计算是独立的,各自状态的计算结果不依赖于其他的状态。每一次状态的计算都是干脆利落的执行,下一个状态计算所需要的资源通过参数传递,上一个状态计算完成之后就没有任何用处了,它不必为前一个或者后一个状态来保存什么有用的信息,需要的信息都根据参数传递给新的状态了。而且,在不断计算的过程中,由于把所需要的值的信息一直作为参数传递,一旦得出了最终的结果,不用像递归一样,把计算结果返回给上一个状态,而是直接返回给一开始的调用者。过程的调用都是在栈空间来开辟内存的,根据以上计算特点,上一个状态计算结束之后可以立即销毁之前所用的栈空间,避免了栈溢出。
这样的计算进程,很容易就可以看出来,时间复杂度O(N),空间复杂度,因为每次计算只需要保存三个变量,它不随n的变化而变化,则为O(1),常量级。不仅仅是这个计算过程这样,计算机当中所有的计算的空间复杂度都应该在常数级别下完成,因为内存空间是有限的。
上述计算进程被称为迭代,如果单就这个实例来说,应该是线性迭代进程。
迭代和递归的区别
- 在迭代的进程中,每个状态计算所需的信息都保存在了几个变量中,通过参数传递过去,不需要额外的再开辟栈空间来保存一些隐含的信息。但是递归是需要的,还存在着栈溢出的危险。
- 在迭代的进程中,如果我们丢失了一些状态的话,可以从任意一个状态开始继续进行计算,因为计算所需要的信息都保存在几个变量中,即使只剩下中间的一个状态,我们也能够根据计算进程把所有丢失的状态全都算出来。但是如果是递归的话,如果某一个状态的信息丢失了,那么即使它的子状态算出了结果返回给它,因为丢失了一些必要的状态信息,使得计算进程是无法进行下去的。
- 虽然两者都在定义过程的时候调用了自身,但是很显然,迭代的定义过程属于用递归的方式定义过程。递归属于递归计算进程。
黑魔法终极奥义:尾递归
一般的编程语言都是通过循环等一些复杂的结构来描述迭代的,但是在scheme中却可以用递归的形式来描述迭代。
观察上面两个求阶乘的过程,我们可以看到。虽然两者都是调用了自身,用了递归的形式来定义整个过程,表面上都属于递归调用,但是,『递归』版本中,在最后的递归调用之后,还需要进行乘n的操作才算作是完成了此次计算,而在 [迭代]版本中,递归的调用属于最后一个方法,末尾的递归调用执行完,此次的计算也就执行完了,属于该过程的最后一个操作,这就是”尾递归”。尾递归相对于正常的递归来说,它的递归调用处于过程最后,之前过程计算积累的信息对于接下来的这次递归调用的最终结果没有任何影响,那么本次过程调用存储在栈内的信息就可以完全清除。把空间留给之后的递归过程使用。所以说,这意味着如果使用尾递归的方式,是可以实现无限递归的。
尾递归的本质,其实是将递归方法中的需要的“所有状态”通过方法的参数传入下一次调用中。这样上一次的调用就不用再保存一些额外的信息,并且在计算到边界的时候,因为计算的结果一直在累积,所以计算到终点的时候,也就得到的最后的结果,可以直接返回给最开始调用这个方法的调用者。
至于把正常递归转化为尾递归的方法,我觉得比较直接的做法就是,正常递归是从后向前考虑,如果写尾递归,那么就把问题从前向后考虑,并且把所需的信息当做参数传递。
一般来讲,虽然在过程定义上,看起来是递归的,但是实际的计算进程的原理有可能是迭代的,也有可能是递归的,因为,迭代的计算是可以用尾递归来进行定义的。

本文由 TecHug 分享,英文原文及文中图片来自 伯乐在线。

共有{1}条精彩评论