数据科学中的 Spark 入门
Apache Spark 为数据科学提供了许多有价值的工具。随着 Apache Spark 1.3.1 技术预览版的发布,强大的 Data Frame API 也可以在 HDP 上使用数据科学家使用数据挖掘和可视化来帮助构造问题架构并对学习进行微调。Apache Zeppelin 正好能够帮他们做到这些。

Apache Spark 为数据科学提供了许多有价值的工具。随着 Apache Spark 1.3.1 技术预览版的发布,强大的 Data Frame API 也可以在 HDP 上使用数据科学家使用数据挖掘和可视化来帮助构造问题架构并对学习进行微调。Apache Zeppelin 正好能够帮他们做到这些。
Zeppelin 是一个基于 Web 的 notebook 服务器。它基于一个解释器的概念,这个解释器可以绑定到任何语言或数据处理后端。作为 Zeppelin 后端的一种,Zeppelin 实现了 Spark 解释器。其他解释器实现,如 Hive、Markdown、D3 等,也同样可以在 Zeppelin 中使用。
我们将通过一系列的博客文章来描述如何结合使用 Zeppelin、Spark SQL 和 MLLib 来使探索性数据科学简单化。作为这个系列的第一篇文章,我们描述了如何为 HDP2.2 安装/构建 Zeppelin,并揭示一些 Zeppelin 用来做数据挖掘的基本功能。
以下假设 HDP 2.2 和 Spark 已经安装在集群上。
Spark 可以使用 Ambari 2.0 安装成一个 service,或者按照这篇文章的描述下载和配置。
无论使用哪种方法安装,本文将 spark.home 代指 Spark 安装的根目录。
构建 Zeppelin
如果可以的话,在一个非 datanode 或 namenode 的集群节点上构建和运行 Zeppelin。这是为了确保在那个节点上 Zeppelin 有足够的计算资源。
从 github 获取 Zeppelin:
git clone https://github.com/apache/incubator-zeppelin.git cd incubator-zeppelin
使用如下命令构建 Spark 1.3.1 可用的 Zeppelin:
mvn clean install -DskipTests -Pspark-1.3 -Dspark.version=1.3.1 -Phadoop-2.6 -Pyarn
使用如下命令构建 Spark 1.2.1 可用的 Zeppelin:
mvn clean install -DskipTests -Pspark-1.2 -Phadoop-2.6 -Pyarn
在之前的步骤中,Zeppelin、Spark 1.3.1 和 Hadoop 2.6 已经构建好了。现在先确定正在使用的 HDP 的版本:
hdp-select status hadoop-client | sed 's/hadoop-client - (.*)/1/'
这个命令应该输出类似这样的版本号:
2.2.4.2-2
将这个参数记为 hdp.version。
编辑 conf/zeppelin-env.sh 文件添加以下几行:
export HADOOP_CONF_DIR=/etc/hadoop/conf export ZEPPELIN_PORT=10008 export ZEPPELIN_JAVA_OPTS="-Dhdp.version=$hdp.version"
复制 /etc/hive/conf/hive-site.xml到conf/ 文件夹下。
为运行 Zeppelin(比如 zeppelin)的用户在 HDFS 上创建一个目录:
su hdfs hdfs dfs -mkdir /user/zeppelin;hdfs dfs -chown zeppelin:hdfs /user/zeppelin>
使用以下命令运行 Zeppelin:
bin/zeppelin-daemon.sh start
这行命令会启动一个 notebook 服务器并通过端口 10008 提供一个 Web UI。
打开 https://$host:10008 访问 notebooks。点击 Interpreter 标签切换到 Interpreter 页面设置一些属性。
配置Zeppelin
为了在YARN客户端模式下运行解释器,需要在 $SPARK_HOME/conf/spark-defaults.conf 重写以下这些属性:
master yarn-client spark.driver.extraJavaOptions -Dhdp.version=$hdp.version spark.home $spark.home spark.yarn.am.extraJavaOptions -Dhdp.version=$hdp.version spark.yarn.jar $zeppelin.home/interpreter/spark/zeppelin-spark-0.5.0-SNAPSHOT.jar
一旦这些配置更新,Zeppelin 会弹框提醒重启解释器。确认重启后解释器会重新加载配置。
至此,准备工作完成,可以开始使用 Zeppelin notebook 了。
打开 https://$host:10008 你将看到像截图一样的界面:
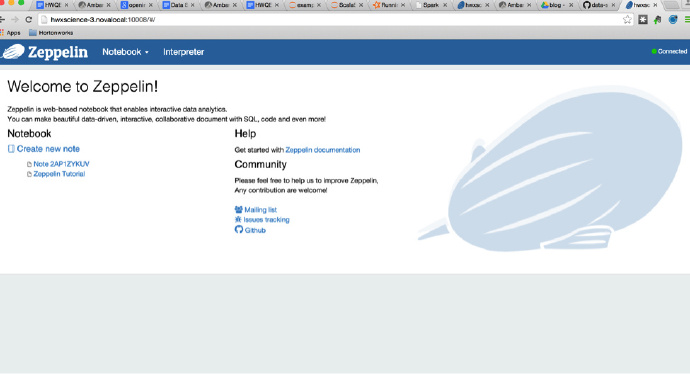
点击 Create new note 来打开一个新的 notebook。
在Notebook中编写Scala
在任一 Ambari 管理的集群上,ambari-agent 日志都写在 /var/log/ambari-agent/ambari-agent.log。
我们将在 Zeppelin 上写一点 Scala 代码来可视化这些日志,从中抽取信息。
为了能看到这些日志的内容并随后处理他们,我们将从这个日志文件创建一个 RDD。
val ambariLogs = sc.textFile("file:///var/log/ambari-agent/ambari-agent.log")
上面的代码将文本文件的内容连结到一个由变量 ambariLogs 代表的 RDD 上。
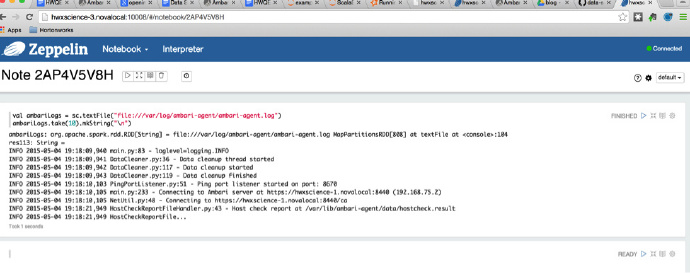
为了能更好地看到日志的内容,使用以下代码 dump 几行文本到解释器终端看看:
ambariLogs.take(10).mkString("n")
这行代码的输出会像这样:
使用Spark SQL
为了进一步分析这些日志,最好将他们与一个 schema 连结起来,并使用 Spark 强大的 SQL 查询功能。
Spark SQL 有一个强大的功能,就是它能够以编程方式把 schema 连接到一个 Data Source,并映射到 Scala 条件类。Scala 条件类能够以类型安全的方式操纵和查询。
对于当前的分析,ambari 日志的每一行可以认为是由以空格隔开的四个基本组件组成的。
- 日志级别(INFO、DEBUG、WARN等)
- 日期(YYYY-mm-dd)
- 时间(HH:mm:ss,SSS格式)
- 文件名
创建一个条件类来连结这个 schema:
// sc is an existing SparkContext. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // this is used to implicitly convert an RDD to a DataFrame. import sqlContext.implicits._ // Define the schema using a case class. import java.sql.Date case class Log(level: String, date: Date, fileName: String)
注意:为了方便,这里将日期和时间合并到一个 Date 对象里。
import java.text.SimpleDateFormat
val df = new SimpleDateFormat("yyyy-mm-dd HH:mm:ss,SSS")
val ambari = ambariLogs.map { line =>
val s = line.split(" ")
val logLevel = s(0)
val dateTime = df.parse(s(1) + " " + s(2))
val fileName = s(3).split(":")(0)
Log(logLevel,new Date(dateTime.getTime()), fileName)}.toDF()
ambari.registerTempTable("ambari")

初始化一个 dataframe 之后,我们可以使用 SQL 在上面做查询。Dataframes 是用来接收针对他们而写的 SQL 查询,并根据需要将查询优化成一系列的 Spark 任务。
比如,假设我们想要得到不同日志级别的事件数量,查询写成 SQL 会是这样的形式:
SELECT level, COUNT(1) from ambari GROUP BY level
但是使用Scala Data Frame API 可以写成:
ambari.groupBy("level").count()
这时,我们可以使用非常接近原生 SQL 的查询:
sqlContext.sql("SELECT level, COUNT(1) from ambari group by level")
这个查询返回的数据结构是根 DataFrame API 返回的是相同的。返回的数据结构本身是一个 data frame。
这个时候并没有任何操作被执行:data frames 上的操作都映射到 RDD 相应的操作(在这个例子中):
RDD.groupBy(...).aggregateByKey(...))
我们可以通过使用 collect() 强制执行这个任务,将结果发送到 driver 的内存中。
使用 Zeppelin 做可视化
Zeppelin Notebook 有一个强大的功能,那就是你可以在同一个框架里看到上一个片段的结果集。Zeppelin 的显示系统接通了标准输出。
任何以 %table、%img、%html 等解释器命令为开头,通过println输出到标准输出的字符串,都可以被 Zeppelin 的显示系统所解析。
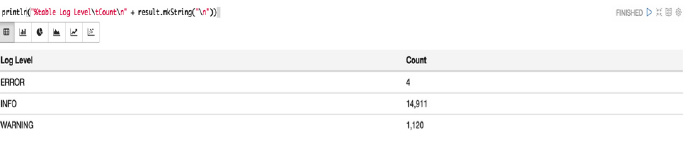
在我们的例子中,我们想要将每种日志级别的日志个数输出成一个表,所以使用以下代码:
import org.apache.spark.sql.Row
val result = sqlContext.sql("SELECT level, COUNT(1) from ambari group by level").map {
case Row(level: String, count: Long) => {
level + "t" + count
}
}.collect()
这段代码将 groupby 的输出整合成表解释器可以渲染的格式。
%table 要求每行数据都以 n(换行符)分隔,每一列均以 t(制表符)分开,如下所示:
println("%table Log LeveltCountn" + result.mkString("n"))
通过这行代码打印出来的结果会是:
总结
数据科学家们使用许多种工具进行工作。Zeppelin 为他们提供了一个新工具来构建出更好的问题。在下一篇文章中,我们将深入讨论一个具体的数据科学问题,并展示如何使用 Zeppelin、Spark SQL 和 MLLib 来创建一个使用 HDP、Spark 和 Zeppelin 的数据科学项目。

本文由 TecHug 分享,英文原文及文中图片来自 伯乐在线。
你也许感兴趣的:
- Python 3.15 的 Windows x86-64 解释器有望提升 15% 运行速度
- C++性能提示
- SQLite是如何做测试的
- 关于首字符下划线及C/C++语言保留的名称
- 将电子墨水平板用作Linux显示器
- D-Bus 是 Linux 桌面的耻辱
- 避免使用 UUID 第 4 版主键(适用于 Postgres)
- 程序员和软件开发者在命名上偏离了正轨
- C语言闭包的代价
- Python中的“冻结”字典

你对本文的反应是: