记一次苦逼的SQL查询优化
最近在维护公司项目时,需要加载某页面,总共加载也就4000多条数据,竟然需要35秒钟,要是数据增长到40000条,我估计好几分钟都搞不定。卧槽,要我是用户的话估计受不了,趁闲着没事,就想把它优化一下,走你。

最近在维护公司项目时,需要加载某页面,总共加载也就4000多条数据,竟然需要35秒钟,要是数据增长到40000条,我估计好几分钟都搞不定。卧槽,要我是用户的话估计受不了,趁闲着没事,就想把它优化一下,走你。
先把查询贴上:
![]()
select Pub_AidBasicInformation.AidBasicInfoId,
Pub_AidBasicInformation.UserName,
Pub_AidBasicInformation.District,
Pub_AidBasicInformation.Street,
Pub_AidBasicInformation.Community,
Pub_AidBasicInformation.DisCard,
Pub_Application.CreateOn AS AppCreateOn,
Pub_User.UserName as DepartmentUserName,
Pub_Consult1.ConsultId,
Pub_Consult1.CaseId,
Clinicaltb.Clinical,AidNametb.AidName,
Pub_Application.IsUseTraining,
Pub_Application.ApplicationId,
tab.num
FROM Pub_Consult1
INNER JOIN Pub_Application ON Pub_Consult1.ApplicationId = Pub_Application.ApplicationId
INNER JOIN Pub_AidBasicInformation ON Pub_Application.AidBasicInfoId = Pub_AidBasicInformation.AidBasicInfoId
INNER JOIN(select ConsultId,dbo.f_GetClinical(ConsultId) as Clinical
from Pub_Consult1) Clinicaltb on Clinicaltb.ConsultId=Pub_Consult1.ConsultId
left join (select distinct ApplicationId, sum(TraniningNumber) as num from dbo.Review_Aid_UseTraining_Record where AidReferralId is null group by ApplicationId) tab on tab.ApplicationId=Pub_Consult1.ApplicationId
INNER JOIN(select ConsultId,dbo.f_GetAidNamebyConsult1(ConsultId) as AidName from Pub_Consult1) AidNametb on AidNametb.ConsultId=Pub_Consult1.ConsultId
LEFT OUTER JOIN Pub_User ON Pub_Application.ReviewUserId = Pub_User.UserId
WHERE Pub_Consult1.Directory = 0
order by Pub_Application.CreateOn desc
![]()
执行后有图有真相:

这么慢,没办法就去看看查询计划是怎么样:
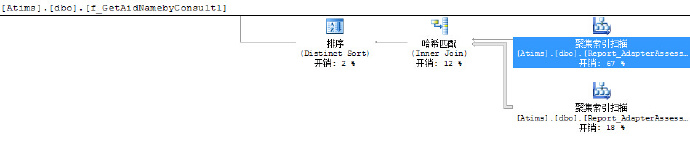

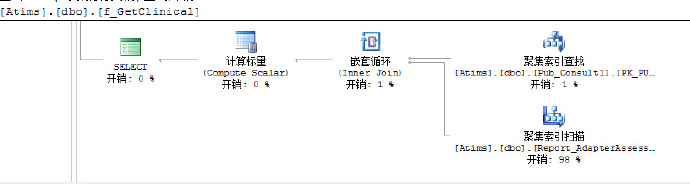
这是该sql查询里面执行三个函数时生成查询计划的截图,一看就知道,执行时开销比较大,而且都是花费在聚集索引扫描上,把鼠标放到聚集索引扫描的方块上面,依次看到如下详细计划:
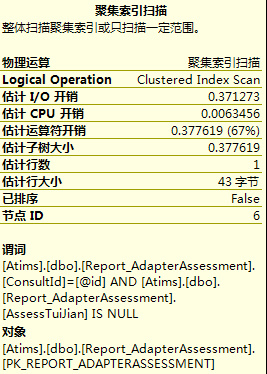
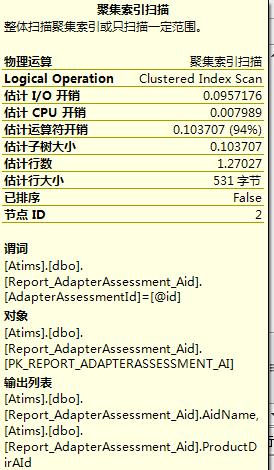

从这几张图里,可以看到查询I/O开销,运算符开销,估计行数,以及操作的对象和查询条件,这些都为优化查询提供了有利证据。第1,3张图IO开销比较大,第2张图估计行数比较大,再根据其它信息,首先想到的应该是去建立索引,不行的话再去改查询。
先看看数据库引擎优化顾问能给我们提供什么优化信息,有时候它能够帮我们提供有效的信息,比如创建统计,索引,分区什么的。
先打开SQL Server Profiler 把刚刚执行的查询另存为跟踪(.trc)文件,再打开数据库引擎优化顾问,做如下图操作
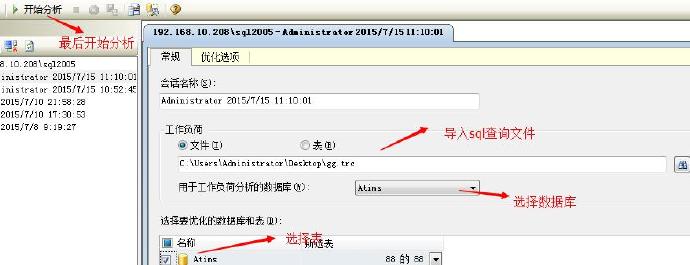
最后生成的建议报告如下:
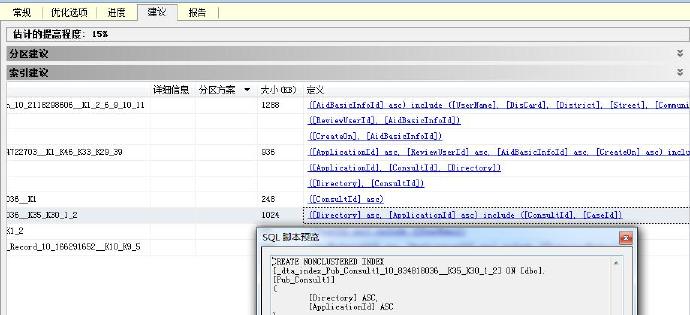
在这里可以单击查看一些建议,分区,创建索引,根据提示创建了如下索引:
CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_AidBasicInformation]
(
[AidBasicInfoId] ASC
)
CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_Application]
(
[ApplicationId] ASC,[ReviewUserId] ASC,[AidBasicInfoId] ASC,[CreateOn] ASC
)
CREATE NONCLUSTERED INDEX index1 ON [dbo].[Pub_Consult1]
(
[Directory] ASC,[ApplicationId] ASC
)
CREATE NONCLUSTERED INDEX idnex1 ON [dbo].[Review_Aid_UseTraining_Record]
(
[AidReferralId] ASC,[ApplicationId] ASC
)
索引创建后,再次执行查询,原以为可提高效率,没想到我勒个去,还是要30几秒,几乎没什么改善,优化引擎顾问有时候也会失灵,在这里只是给大家演示有这种解决方案去解决问题,有时候还是靠谱的,只是这次不靠谱。没办法,只有打开函数仔细瞅瞅,再结合上面的查询计划详细图,删除先前创建的索引,然后创建了如下索引:
CREATE NONCLUSTERED INDEX index1 ON dbo.Report_AdapterAssessment_Aid
(
AdapterAssessmentId ASC, ProductDirAId ASC
)
CREATE NONCLUSTERED INDEX index1 ON dbo.Report_AdapterAssessment
(
ConsultId ASC
)
再次执行查询

好了,只需3.5秒,差不多提高10倍速度,看来这次是凑效了哈。
再来看看查询计划是否有改变,上张图来说明下问题:

从上图当中我们可以看到,索引扫描不见了,只有索引查找,聚集索引查找,键查找,而且运算符开销,I/O开销都降低了很多。索引扫描(Index Scan),聚集索引扫描(Clustered Index Scan)跟表扫描(Table Scan)差不多,基本上是逐行去扫描表记录,速度很慢,而索引查找(Index Seek),聚集索引查找,键查找都相当的快。优化查询的目的就是尽量把那些带有XXXX扫描的去掉,换成XXXX查找。
这样够了吗?但是回头又想想,4000多条数据得3.5秒钟,还是有点慢了,应该还能再快点,所以决定再去修改查询。看看查询,能优化的也只有那个三个函数了。
为了看函数执行效果先删除索引,看看查询中函数f_GetAidNamebyConsult1要干的事情,截取查询中与该函数有关的子查询:
select Pub_Consult1.ConsultId,AidName from (select ConsultId,dbo.f_GetAidNamebyConsult1(ConsultId) as AidName from Pub_Consult1) AidNametb inner join Pub_Consult1 on AidNametb.ConsultId=Pub_Consult1.ConsultId
得到下图的结果:

没想到就这么点数据竟然要46秒,看来这个函数真的是罪魁祸首。
该函数的具体代码就不贴出来了,而且该函数里面还欠套的另外一个函数,本身函数执行起来就慢,更何况还函数里子查询还包含函数。其实根据几相关联的表去查询几个字段,并且把一个字段的值合并到同一行,这样没必要用函数或存储过程,用子查询再加sql for xml path就行了,把该函数改成如下查询:
with cte1 as
(
select A.AdapterAssessmentId,case when B.AidName is null then A .AidName else B.AidName end AidName
from Report_AdapterAssessment_Aid as A left join Pub_ProductDir as B
on A.ProductDirAId=B.ProductDirAId
),
cte2 as
(
--根据AdapterAssessmentId分组并合并AidName字段值
select AdapterAssessmentId,(select AidName+',' from cte1
where AdapterAssessmentId= tb.AdapterAssessmentId
for xml path(''))as AidName
from cte1 as tb
group by AdapterAssessmentId
),
cte3 as
(
select ConsultId,LEFT(AidName,LEN(AidName)-1) as AidName
from
(
select Pub_Consult1.ConsultId,cte2.AidName from Pub_Consult1,Report_AdapterAssessment,cte2
where Pub_Consult1.ConsultId=Report_AdapterAssessment.ConsultId
and Report_AdapterAssessment.AdapterAssessmentId=cte2.AdapterAssessmentId
and Report_AdapterAssessment.AssessTuiJian is null
) as tb)
这样查询出来的结果在没有索引的情况下不到1秒钟就行了。再把主查询写了:
select distinct Pub_AidBasicInformation.AidBasicInfoId,
Pub_AidBasicInformation.UserName,
Pub_AidBasicInformation.District,
Pub_AidBasicInformation.Street,
Pub_AidBasicInformation.Community,
Pub_AidBasicInformation.DisCard,
Pub_Application.CreateOn AS AppCreateOn,
Pub_User.UserName as DepartmentUserName,
Pub_Consult1.ConsultId,
Pub_Consult1.CaseId,
Clinicaltb.Clinical,
cte3.AidName,
Pub_Application.IsUseTraining,
Pub_Application.ApplicationId,
tab.num
from Pub_Consult1
INNER JOIN Pub_Application ON Pub_Consult1.ApplicationId = Pub_Application.ApplicationId
INNER JOIN Pub_AidBasicInformation ON Pub_Application.AidBasicInfoId = Pub_AidBasicInformation.AidBasicInfoId
INNER JOIN(select ConsultId,dbo.f_GetClinical(ConsultId) as Clinical
from Pub_Consult1) Clinicaltb on Clinicaltb.ConsultId=Pub_Consult1.ConsultId
left join (select distinct ApplicationId, sum(TraniningNumber) as num from dbo.Review_Aid_UseTraining_Record
where AidReferralId is null
group by ApplicationId) tab
on tab.ApplicationId=Pub_Consult1.ApplicationId
left JOIN cte3 on cte3.ConsultId=Pub_Consult1.ConsultId
LEFT OUTER JOIN Pub_User ON Pub_Application.ReviewUserId = Pub_User.UserId
where Pub_Consult1.Directory = 0
order by Pub_Application.CreateOn desc
这样基本上就完事了,在没有建立索引的情况下需要8秒钟,比没索引用函数还是快了27秒。

把索引放进去,就只需1.6秒了,比建立索引用函数而不用子查询和sql for xml path快了1.9秒
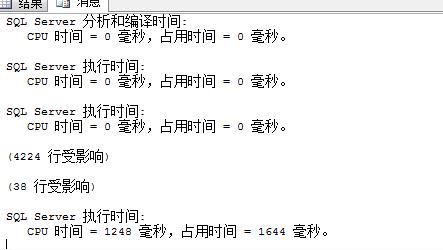
查询里面还有个地方用了函数,估计再优化下还能提高执行效率,因为时间有限再加上篇幅有点长了,在这里就不多讲了。
最后做个总结吧,查询优化不外乎以下这几种办法:
1:增加索引或重建索引。通常在外键,连接字段,排序字段,过滤查询的字段建立索引,也可通过数据库引擎优化顾问提供的信息去建索引。有时候当你创建索引时,会发现查询还是按照索引扫描或聚集索引扫描的方式去执行,而没有去索引查找,这时很可能是你的查询字段和where条件字段没有全部包含在索引字段当中,解决这个问题的办法就是多建立索引,或者在创建索引时Include相应的字段,让索引字段覆盖你的查询字段和where条件字段。
2:调整查询语句,前提要先看懂别人的查询,搞清楚业务逻辑。
3:表分区,大数据量可以考虑。
4:提高服务器硬件配置。

本文由 TecHug 分享,英文原文及文中图片来自 博客园。
你也许感兴趣的:
- Python 3.15 的 Windows x86-64 解释器有望提升 15% 运行速度
- C++性能提示
- SQLite是如何做测试的
- 关于首字符下划线及C/C++语言保留的名称
- 将电子墨水平板用作Linux显示器
- D-Bus 是 Linux 桌面的耻辱
- 避免使用 UUID 第 4 版主键(适用于 Postgres)
- 程序员和软件开发者在命名上偏离了正轨
- C语言闭包的代价
- Python中的“冻结”字典

你对本文的反应是: