【译文】谷歌测试技术:如何大规模代码删除
自动删除代码听起来可能是个奇怪的想法:编写代码的成本很高,而且通常被认为是一种资产。然而,未使用的代码无论是维护还是清理都需要花费时间和精力。一旦代码库达到一定规模,投入工程时间进行自动清理流程就开始变得有意义了

大规模代码库
在谷歌,数以万计的软件工程师为一个数十亿行的单一代码库做出贡献。该库存储在一个名为 Piper 的系统中,包含共享库、生产服务、实验程序、诊断和调试工具的源代码:基本上所有与代码相关的内容。
这种开放式方法非常强大。例如,如果工程师不确定如何使用某个库,他们可以通过搜索找到示例。它还允许好友在整个资源库中执行重要的更新,无论是迁移到更新的 API,还是跟随语言的升级(如 Python 3 或 Go 泛型)。
然而,代码并不是免费的:它不仅生产成本高昂,维护起来也需要花费大量的工程时间。这种维护工作不能轻易省略,至少如果想避免日后付出更大的代价的话。
但如果需要维护的代码更少呢?这些代码真的有必要吗?
大规模删除
任何大型项目都会积累死代码:总会有一些模块不再需要,或者一个程序在早期开发时使用过,但多年来一直没有运行。事实上,整个项目在创建、运行一段时间后就不再有用了。有时会对它们进行清理,但清理工作需要时间和精力,而且要证明这种投资是合理的并不容易。
然而,虽然这些死代码没有被删除,但仍在产生成本:自动测试系统不知道它应该停止运行死测试;进行大规模清理的人员不知道迁移这些代码没有意义,因为它们根本不会被运行。
那么,如果我们能自动清理死代码呢?几年前,在苏黎世工程生产力团队的年度黑客马拉松活动中,人们就开始思考这个问题。Sensenmann 项目以德语 “死亡的化身 “命名,取得了巨大成功。它每周提交 1000 多份删除更改列表,迄今已删除了谷歌近 5% 的 C++。
它的目标很简单(至少原则上如此):自动识别死亡代码,并发送代码审查请求(”变更列表”)将其删除。
删除什么?
谷歌的构建系统 Blaze(Bazel 的内部版本)可以帮助我们确定这一点:通过以一致且可访问的方式表示二进制目标、库、测试、源文件等之间的依赖关系,我们可以构建一个依赖关系图。这样,我们就能找到未链接到任何二进制文件的库,并建议删除它们。
但这只是问题的一小部分:那些二进制文件怎么办?所有的一次性数据迁移程序和过时系统的诊断工具?如果它们不被删除,那么它们所依赖的所有库也会被保留下来。
因此,对于内部二进制程序(在谷歌数据中心或员工工作站上运行的程序),程序运行时会写入日志,记录时间和具体是哪个二进制程序。通过汇总这些信息,我们就能为谷歌使用的每个二进制文件获得一个 “有效性 “信号。如果某个程序长时间未被使用,我们就会尝试发送删除更新列表。
哪些内容不能删除?
当然,也有例外情况:有些程序代码只是作为如何使用 API 的示例;有些程序只在我们无法获取日志信号的地方运行。还有许多其他例外情况,在这些情况下,删除这些代码将是有害的。因此,我们必须建立一个拦截列表系统,以便对例外情况进行标记,避免用虚假的变更列表来打扰别人。
细节决定成败
考虑一个简单的例子。我们有两个二进制文件,每个文件都依赖于自己的库,同时也依赖于第三个共享库。将其绘制出来(忽略源文件和其他依赖关系),我们会发现这样一种结构:
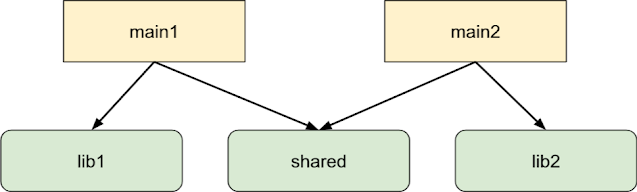
如果我们发现 main1 正在使用中,而 main2 最后一次使用是在一年多以前,我们就可以在构建树中传播 “有效性 “信号,将 main1 及其依赖的所有内容标记为 “有效”。剩下的部分可以删除;由于 main2 依赖于 lib2,我们希望在同一变更中删除这两个目标:
到目前为止一切顺利,但真正的生产代码需要进行单元测试,而单元测试的构建目标取决于其测试的库。这样一来,图形遍历就变得复杂多了:
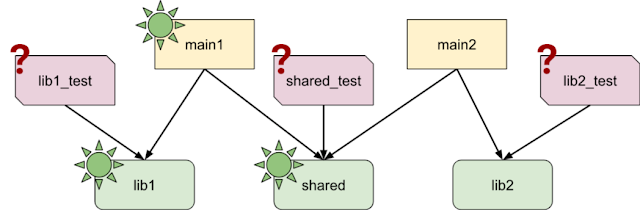
尽管 lib2 从未被 “真正 “执行过,测试基础架构还是会运行包括 lib2_test 在内的所有测试。这意味着我们不能使用测试运行作为 “有效性 “信号:如果这样做,我们就会认为 lib2_test 是有生命的,这样 lib2 就会永远存在。我们只能清理未经测试的代码,这将严重影响我们的工作。
我们真正想要的是让每个测试与它所测试的库共命运。我们可以通过使库及其测试相互依赖来实现这一点,从而在图中创建循环:
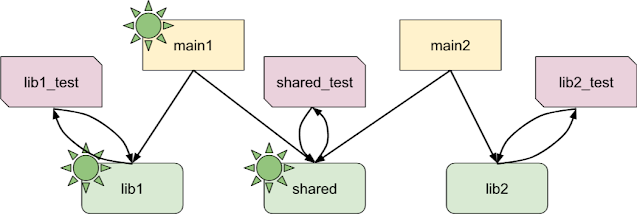
这样,每个库及其测试就变成了一个强连接组件。我们可以使用与之前相同的技术,标记 “活 “节点,然后寻找要删除的 “死 “节点集合,但这次要使用 Tarjan 的强连接组件算法来处理循环。
很简单吧?是的,如果很容易识别测试与所测试的库之间的关系的话。遗憾的是,情况并非总是如此。在上面的例子中,有一个简单的命名约定可以让我们将测试与库匹配起来,但在一般情况下,我们不能依赖这种启发式方法。
请考虑以下两种情况:
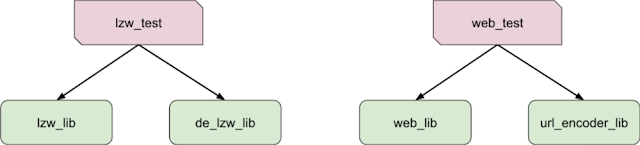
左边是 LZW 压缩算法的实现,分别是压缩器和解压缩器库。该测试实际上是同时测试这两个库,以确保数据在压缩和解压缩后不会损坏。在右侧,我们有一个 web_test 测试我们的网络服务器库;它使用 URL 编码器库作为支持,但实际上并不测试 URL 编码器本身。在左边,我们希望将 LZW 测试和两个 LZW 库视为一个相连的组件,但在右边,我们希望排除 URL 编码器,将 web_test 和 web_lib 视为相连的组件。
尽管需要不同的处理方法,但这两种情况具有相同的结构。在实践中,我们可以鼓励工程师将类似 url_encoder_lib 这样的库标记为 “仅用于测试”(即仅用于支持单元测试),这对 web-test 案例很有帮助;否则,我们目前的方法就是使用测试和库名之间的编辑距离来挑选最有可能与给定测试相匹配的库。要识别像 LZW 示例(一个测试和两个库)这样的情况,很可能需要处理测试覆盖率数据,目前尚未对此进行探索。
关注用户…
虽然死代码删除的最终受益者是软件工程师本身,他们中的许多人都非常感激这种帮助,因为他们可以保持项目的整洁,但并不是每个人都乐意收到自动更新列表,试图删除自己编写的代码。这就是项目的社会工程方面,它与软件工程同等重要。
对许多工程师来说,自动删除代码是一个陌生的概念,就像 20 年前引入单元测试一样,许多人对它有抵触情绪。要改变人们的想法需要时间和努力,还需要大量细致的沟通。
Sensenmann 的沟通策略主要分为三个部分。最重要的是变更说明,因为这是审核人员首先看到的内容。这些说明必须简明扼要,但必须提供足够的背景资料,以便所有评审人员做出判断。这是很难做到的平衡:太短,很多人就找不到他们需要的信息;太长,最后就会变成一堵文字墙,没有人愿意去读。标注清楚的辅助文档链接和常见问题在这方面确实很有帮助。
第二部分是辅助文件。简洁明了的措辞和良好的导航结构在这里也至关重要。不同的人需要不同的信息:有些人需要保证,在源代码控制系统中,删除的内容是可以回滚的;有些人则需要指导,如何以最佳方式处理糟糕的变更,例如修正对构建系统的误用。经过深思熟虑和用户反馈的反复推敲,辅助文档可以成为有用的资源。
第三部分是处理用户反馈。这有时可能是最难的部分:反馈往往是负面的多于正面的,有时需要冷静的头脑和良好的外交技巧。然而,接受这些反馈意见是改进系统、让用户更满意、从而避免今后出现负面反馈意见的最佳途径。
不断前进
自动删除代码听起来可能是个奇怪的想法:编写代码的成本很高,而且通常被认为是一种资产。然而,未使用的代码无论是维护还是清理都需要花费时间和精力。一旦代码库达到一定规模,投入工程时间进行自动清理流程就开始变得有意义了。据估计,在谷歌这样的规模上,自动删除代码所节省的维护成本是其本身成本的数十倍。
实施过程中需要解决技术和社会两方面的问题。虽然在这两方面都取得了很大进展,但还没有完全解决。不过,随着改进的进行,删除的接受率会越来越高,自动删除的影响也会越来越大。这种投资不会在所有地方都有意义,但如果你有一个庞大的单一存储库,也许对你也有意义。至少在谷歌,减少 5% 的 C++ 维护负担是一个巨大的胜利。

本文由 TecHug 分享,英文原文及文中图片来自 Sensenmann: Code Deletion at Scale。
你也许感兴趣的:
- 开发人员和测试人员
- 【外评】谷歌测试:复杂难读的布尔表达式
- 设计的付出、开发的付出对比写单元测试和自动化测试脚本的付出
- 【外评】谷歌对测试的分类
- 【译文】谷歌测试技术:多少测试才算足够?
- Sentry 的前端测试实践:从 Enzyme 迁移到 RTL
- 2021年10大流行软件测试工具
- 谈一谈程序员不愿意写测试的问题
- 程序员文史综合素质测试题,下跪吧
- 为什么说让程序员自己做测试等于白测

你对本文的反应是: