





英伟达技术的曙光
由于 Nvidia 成为全球最有价值的公司之一,现在有两本书解释了它的崛起并颂扬了黄仁勋的天才,一本是 Tae Kim 的《Nvidia 之道》: Tae Kim 的《英伟达之道:黄仁生与科技巨头的诞生》和 Steven Witt 的《思考机器》: Jensen Huang, Nvidia, and the World’s Most Coveted Microchip》。对于后面 90% 的历史,我并不在现场,所以我不会对他们对这部分的处理发表评论。但对于sun微系统公司的前史和前 10%的历史,我都在现场。金对这一时期业务方面的描述非常详细,虽然是三十年前的事了,但与我的回忆不谋而合。
维特对早期历史的业务方面的描述则要详细得多,有些细节与我的记忆不符。
但就早期历史的技术方面而言,两位作者似乎都没有真正理解我们进行成像模式和 I/O 架构这两种创新的原因。维特写道(第 31 页):
我第一次向普里姆询问 NV1 的结构时,他不间断地讲了二十七分钟。
在下面,我试图解释柯蒂斯在这 27 分钟里讲了些什么。这将需要我写一篇很长的文章。
背景介绍

Swaaye, CC-By-SA 3.0
在《长期工程》的 “三十年 ”部分,我写道
当我们创办 Nvidia 时,我们看到的机遇是 PC 正在从 PC/AT 总线向第一版 PCI 总线过渡。PC/AT 总线的带宽完全不能满足 3D 游戏的需要,而 PCI 总线的带宽却大大增加。至于是否足够,这还是个未知数。我们显然需要尽可能充分利用有限的带宽。
我们有两种 “充分利用有限带宽 ”的基本方法:
- 减少特定图像在总线上传输的数据量。
- 增加总线每个周期传输的数据量。
成像模型
三角形是对表面最简单的描述。因此,几乎整个 3D 计算机图形学的历史都是使用三角形对 3D 物体的表面进行建模。但有一种技术,至少可以追溯到 1972 年罗伯特-马赫尔(Robert Mahl)发表的论文《四边形补丁的可见表面算法》(Visible Surface Algorithms for Quadric Patches),可以直接为曲面建模。与三角形相比,描述一个四边形补丁需要更多的数据。但要达到相同的逼真度,你需要的补丁数量要少得多,以至于每帧的数据量要减少很多。
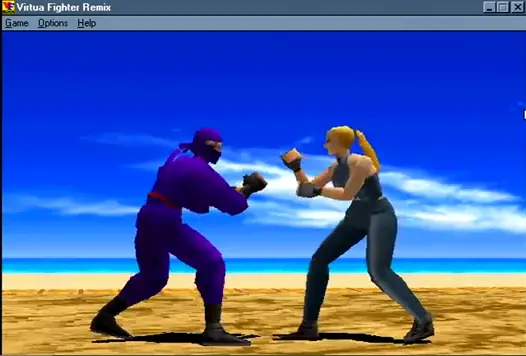
据我所知,当时视频游戏行业中只有世嘉公司使用了四边形贴片。当我们在 Comdex 上推出 NV1 时,我们能够在 PC 上以全帧率运行世嘉街机游戏,如 Virtua Fighter,这在业内尚属首次。原因是 NV1 使用了四元补丁,从而更好地利用了有限的 PCI 总线带宽。
在 Sun 公司,我和詹姆斯-高斯林(James Gosling)开发了极为复杂、具有前瞻性的专有 NeWS 视窗系统。与此同时,我还与竞争对手(如数字设备公司)的工程师一起开发了 X Window System。在 X 视窗系统的漫长历史中,我在 Sun 的许多学习经历之一就是在早期。我很快就发现,NeWS 无法与简单得多的开源 X 竞争。我主张 Sun 放弃 NeWS,采用 X,因为这才是应用程序开发人员想要的。太阳公司浪费了宝贵的时间,却无法决定该怎么做,最后决定不做决定,并浪费了大量资源,将 NeWS 和 X 合并成一个比其前身更糟糕的 NeWS 和 X。这只是我在 Sun 输掉的几场战斗中的一场(这是另一场)。
当微软发布 Direct X 后,我很明显地意识到,如果 Nvidia 的下一代芯片采用四角形补丁,那么 Nvidia 就完蛋了,因为开发人员将不得不使用 Direct X 的三角形。但是,就像 Sun 公司一样,Nvidia 似乎无法决定放弃自己珍视的技术。做出有效决定的时间悄然流逝。我辞职了,希望能改变现状,从而做出采用三角形的决定。这一定起了作用。书中记述了 RIVA 128 上市时,Nvidia 公司濒临破产。剩下的就是历史了,而我只是一个旁观者。
输入/输出架构
相比之下,随着时间的推移,I/O架构取得了我们计划中的巨大成功。Kim 写道(第 95 页):
早期,柯蒂斯-普里姆发明了一种 “虚拟化对象 ”架构,并将其应用于 Nvidia 的所有芯片中。一旦 Nvidia 采用更快的芯片发布节奏,这种架构就会成为公司更大的优势。普里姆的设计有一个基于软件的 “资源管理器”,本质上是硬件本身之上的一个微型操作系统。资源管理器允许 Nvidia 的工程师模拟某些硬件功能,而这些功能通常需要物理印刷到芯片电路上。这涉及到性能成本,但却加快了创新步伐,因为 Nvidia 的工程师可以冒更大的风险。如果新功能还不能在硬件上运行,Nvidia 可以在软件上进行仿真。与此同时,工程师还可以在有足够剩余计算能力的情况下取消硬件功能,从而节省芯片面积。
对于 Nvidia 的大多数竞争对手来说,如果芯片上的硬件功能尚未准备就绪,就意味着进度落后。但在 Nvidia 却不是这样,这要归功于 Priem 的创新。“迈克尔-哈拉(Michael Hara)说:”这是这个星球上最聪明的东西。“这是我们的秘诀。如果我们漏掉了一个功能或一个功能被破坏了,我们可以把它放到资源管理器中,它就会工作。Nvidia 销售主管杰夫-费舍尔(Jeff Fisher)也认为:”Priem 的架构对于 Nvidia 更快地设计和制造新产品至关重要。
背景
Nvidia 只是 Sun Microsystems 催生的众多初创公司之一。但在当时,让 Nvidia 在竞争激烈的图形初创公司中独树一帜的,是来自 Sun 打造 GX 系列图形芯片团队的早期工程师们。我们在 Unix(一种多进程、虚拟内存的操作系统)中接受了有关有效实施图形技术的密集教育。我们的竞争对手都来自 Windows 背景,当时的 Windows 是单进程、非虚拟内存系统。我们明白,在可预见的未来,Windows 必须发展多进程和虚拟内存。因此,我们向风险投资公司提出的建议是,我们将设计一种 “面向未来 ”的架构,并为 PC 的未来操作系统提供 Unix 图形芯片。
GX 团队还从 Sun 公司的外围设备交付困难中汲取了经验,由于操作系统驱动程序和应用程序需要详细了解物理硬件,因此软件和硬件的日程安排是不可分割的。这导致了 “发射台鸡肋 ”现象,因为双方都试图将进度延误归咎于对方。
写入为主
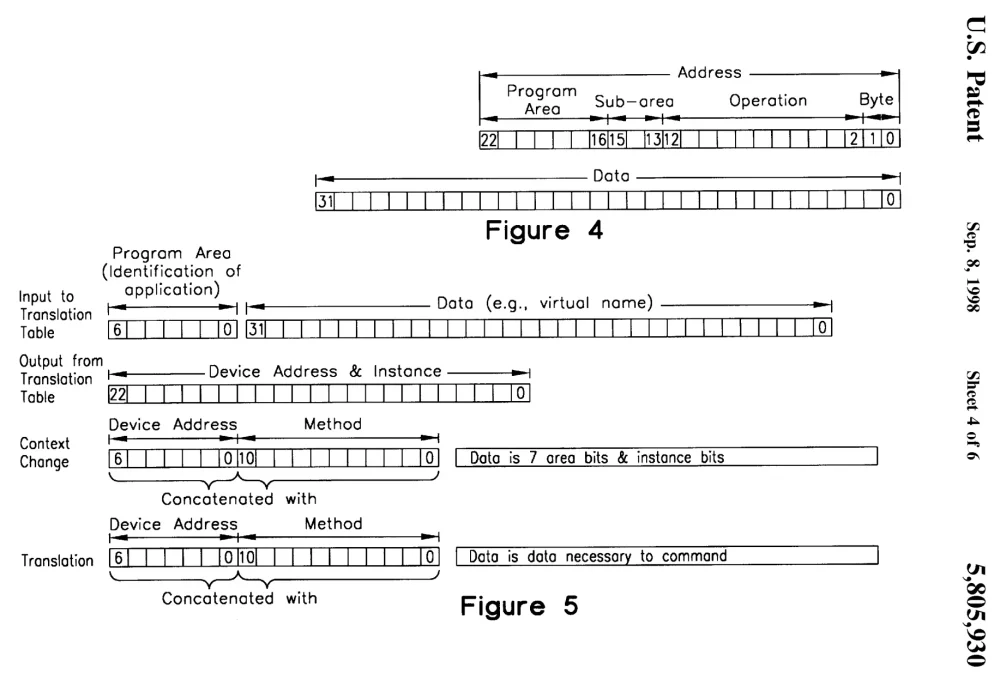
我们在 US5918050A 中是这样解释这个问题的: 从物理 I/O 地址访问的装置,用于地址和数据转换以及 I/O 设备的上下文切换,以响应应用程序的命令(发明人:David S. H. Rosenthal 和 Curtis Priem),使用 “PDP11 架构 ”作为系统的简称,其 I/O 寄存器映射到与系统内存相同的地址空间:
输入/输出操作不仅必须由操作系统软件来执行,采用 PDP11 架构的计算机设计通常还要求中央处理单元读取每个输入/输出设备的寄存器,以便完成任何输入/输出操作。为了加快 PDP11 型系统的运行速度,中央处理单元的速度越来越快,因此有必要对输入/输出总线上的写操作进行缓冲,因为总线的速度跟不上中央处理单元的速度。因此,每个写入操作都由中央处理单元传送到一个缓冲区,在那里排队等待处理;中央处理单元和输入/输出设备之间线路上的其他缓冲区也有类似功能。在进行读取操作之前,所有这些写入缓冲区都必须以串行顺序执行排队操作,以保持正确的操作顺序。因此,中央处理单元若要读取输入/输出设备寄存器中的数据,必须等到所有写入缓冲区被刷新后,才能访问总线完成读取操作。典型的系统在发生读操作时,其队列中平均会有 8 个写操作,必须先处理完所有这些写操作,才能处理读操作。这使得读操作比写操作慢得多。由于中央处理器在图形方面的许多操作都需要读取帧缓冲区中的大量像素,然后转换这些像素,最后将它们重写到新的位置,因此图形操作变得异常缓慢。事实上,现代图形操作是最先暴露 PDP11 架构这一致命弱点的操作。
我们采取了两种方法来避免阻塞 CPU。首先,我们在设备中实现了一个相当长的队列,即 FIFO(先进先出),我们允许 CPU 从 FIFO 中读取空闲槽位的数量,即它可以完成的写入次数,并保证不会阻塞。当 CPU 想要写入 NV1 时,它会询问 FIFO 可以写入多少次。如果答案是 N,它就会写 N 次,然后再询问一次。NV1 会立即确认每次写入,允许 CPU 继续计算下一次写入的数据。这就是 US5805930A 的主题: FIFO 通知阶段可用性以存储命令的系统,这些命令包括从应用程序直接发送的数据和虚拟地址(发明人:David S. H. Rosenthal 和 Curtis Priem),这是我们于 1995 年 5 月 15 日提交的申请的延续。请注意,这意味着应用程序无需知道设备 FIFO 的大小。如果未来的芯片有更大或更小的 FIFO,不变的应用程序也能正确使用。
其次,我们尽可能不使用 CPU 与 NV1 之间传输数据。相反,我们尽可能使用直接内存访问(Direct Memory Access),即 I/O 设备独立于 CPU 读写系统内存。在大多数情况下,中央处理器通过一次或几次写入指令 NV1 执行某些操作,然后继续执行其程序。该指令通常会说:“内存中有一个四元补丁块,请您渲染”。如果 CPU 需要答案,它就会告诉 NV1 在系统内存中的哪个位置放置答案,并每隔一段时间检查答案是否到达。
请记住,我们是为虚拟内存系统创建这一架构的,在虚拟内存系统中,应用程序可直接访问 I/O 设备。应用程序以虚拟地址寻址系统内存。系统的内存管理单元(MMU)将这些地址转换为总线使用的物理地址。当应用程序告诉设备补丁块的地址时,它只能向设备发送一个虚拟地址。要从系统内存中获取补丁,设备上的 DMA 引擎需要像 CPU 的 MMU 一样,将虚拟地址转换为总线上的物理地址。
因此,NV1 不仅有一个 DMA 引擎,还有一个 IOMMU。我们为这个 IOMMU 申请了 US5758182A 专利:DMA 控制器将直接从应用程序命令接收到的虚拟 I/O 设备地址转换为设备总线上 I/O 设备的物理 I/O 设备地址(发明人:David S. H. Rosenthal 和 Curtis Priem)。在 2014 年的《硬件 I/O 虚拟化》一书中,我解释了亚马逊最终是如何为 AWS 数据中心的服务器构建带有 IOMMU 的网络接口,从而让多个虚拟机可以直接访问网络硬件,从而消除操作系统开销的。
上下文切换
在 Unix(以及后来的 Linux、Windows、MacOS……)等多进程操作系统中,图形支持的根本问题是如何让多个进程产生错觉,以为每个进程都能独占访问单个图形设备。我于 1983 年在卡内基-梅隆大学开始解决这个问题。我和詹姆斯-高斯林(James Gosling)创建了安德鲁窗口系统(Andrew Window System),该系统允许多个进程在各自的窗口中共享屏幕。但他们无法访问真正的硬件。只有一个服务器进程可以访问真正的硬件。应用程序向服务器进行远程过程调用(RPC),而服务器则实际绘制所需的图形。四十年后的今天,X 窗口系统仍以这种方式运行。
RPC 带来的性能损失使得 3D 游戏无法使用。举例来说,为了让游戏在一个窗口中运行,而邮件程序在另一个窗口中运行,我们需要让当前活动进程直接访问硬件,如果操作系统上下文切换到不同的图形进程,则让该进程直接访问硬件。操作系统需要从图形硬件中保存第一个进程的状态,并恢复第二个进程的状态。
我们在 Sun 就这一问题开展的工作促成了 1989 年申请的一项专利,即 US5127098A:设备上下文切换的方法和设备(发明人:David S. H. Rosenthal、Robert Rocchetti、Curtis Priem 和 Chris Malachowsky)。他们的想法是将设备映射到每个进程的内存中,但利用系统的内存管理单元(MMU)确保在任何时候,除了一个映射之外,所有映射都是无效的。进程对无效映射的访问将中断到系统的页面故障处理程序,该程序将调用设备的驱动程序保存旧进程的上下文并恢复新进程的上下文。这种想法的一般问题在于,由于中断最终会进入页面故障处理程序,因此需要在页面故障处理程序中编写依赖于设备的代码。这正是软件和硬件之间的联系,也正是这种联系导致了 Sun 公司的进度问题。
Nvidia 的这一想法有两个具体问题。首先,Windows 并非虚拟内存操作系统,因此无法实现这些功能。其次,即使 Windows 已经进化成虚拟内存操作系统,微软也不可能让我们乱用页面故障处理程序。
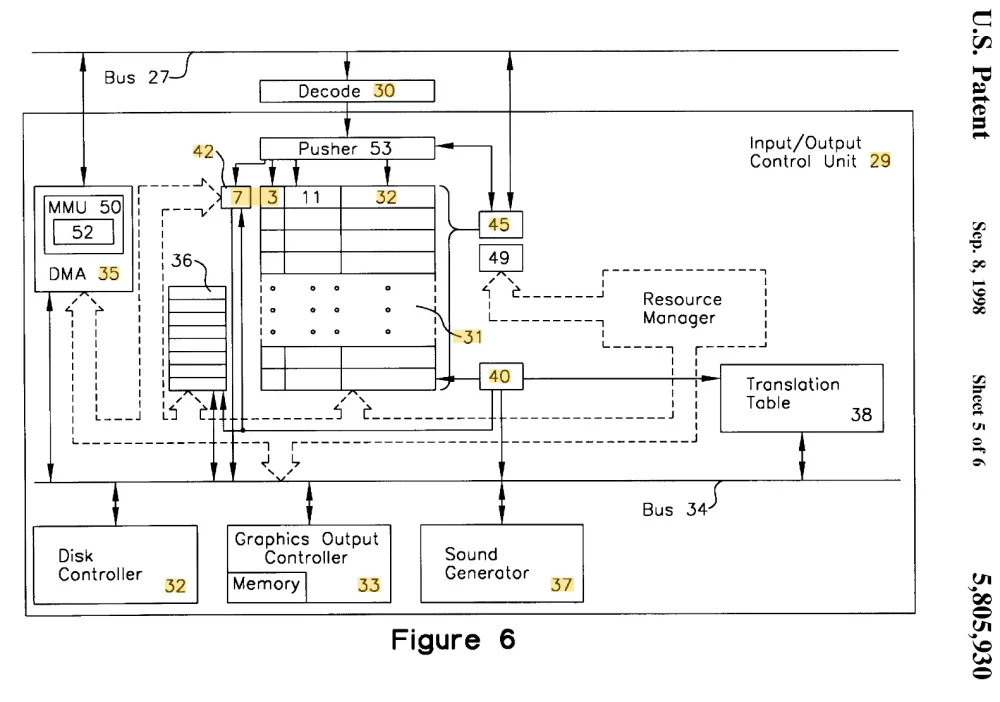
从 930 号专利的图 6 中可以看到,I/O 架构由 PCI 总线和内部总线之间的接口组成,内部总线可实现多种不同的 I/O 设备。该接口具有多种功能:
- 它实现了 FIFO,在内部总线上的所有设备之间共享。
- 它实现了 DMA 引擎及其 IOMMU,并在内部总线上的所有设备之间共享。
- 它使用一个转换表,允许应用程序使用虚拟名称通过接口连接到内部总线上的特定设备。
- 它确保一次只能有一个应用程序访问接口。
PCI 总线与 PC/AT 总线的区别不仅在于数据路径从 16 位增加到 32 位,而且在于地址总线从 24 位增加到 32 位。地址空间扩大了 256 倍,因此 Nvidia 的设备可以占用更多的空间。我们可以实现许多虚拟 FIFO,这样每个应用程序都可以对其中一个进行有效映射。设备而不是操作系统将确保只有一个虚拟 FIFO 映射到单个物理 FIFO。访问未映射到物理 FIFO 的虚拟 FIFO 的进程将导致中断,但这次中断将转到设备的驱动程序,而不是页面故障处理程序。驱动程序可以执行上下文切换,并将物理 FIFO 重新分配给新的虚拟 FIFO。它还必须将 CPU 的 MMU 中的页表项复制到 IOMMU 中,以反映新进程在物理内存中的页位置。由于不存在页面故障,因此操作系统的页面故障处理程序中不存在设备知识。正如我们在 050 号专利中所写的那样
使用许多大小相同的输入/输出设备地址空间,每个地址空间只分配给一个应用程序使用,这样就可以利用输入/输出地址来确定是哪个应用程序启动了任何特定的输入/输出写入操作。
由于每个应用程序都有自己的虚拟 FIFO,因此未来的芯片可以实现多个物理 FIFO,允许为多个进程的虚拟 FIFO 分配一个物理 FIFO,从而减少上下文切换的需要。
对象与方法
NeWS 的一大亮点是使用 PostScript 编程。我们已经知道如何让PostScript面向对象,与SmallTalk同构。我们将窗口系统中的对象组织成一个具有继承性的类层次结构。例如,这使得唐-霍普金斯可以为 NeWS 实现饼形菜单,任何用户都可以用饼形菜单取代传统的矩形菜单。这非常有趣,我和欧文-邓斯莫尔(Owen Densmore)用同样的技术为 Unix shell 实现了面向对象编程。
当时,PC 内存的最大容量为 640 兆字节,而 PCI 总线可以寻址 4 千兆字节,这意味着它的很多地址位都是多余的。因此,我们决定将其中一些作为数据使用,以增加每个总线周期的数据传输量。NV1 使用了 23 个地址位,占总空间的 1/512。23 个地址位中的 7 个选择了 128 个虚拟 FIFO 中的一个,允许 128 个不同进程共享硬件访问权限。我们认为 128 个进程已经足够了。
其余 16 个地址位可用作数据。理论上,FIFO 的宽度可以达到 48 位,其中 32 位来自总线上的数据线,16 位来自地址线,每个总线周期的位数增加了 50%。NV1 忽略了地址的字节部分,因此 FIFO 的宽度只有 46 位。
因此,我们将 I/O 架构中的对象组织成一个类层次结构,根植于类 CLASS。应用程序要做的第一件事就是在代表类 CLASS 的对象上调用 enumerate() 方法。这将返回 CLASS 类所有实例的名称列表,即该架构实例实现的所有对象类型。通过这种方式,设备的功能并没有被连接到应用程序中。应用程序会询问设备的功能。反过来,应用程序可以对列表中 CLASS 类的每个实例调用 enumerate(),这将使应用程序获得每个类(可能是 LINE-DRAWER)的每个实例的名称列表。这样,应用程序就可以找出而不是先验地知道设备支持的所有不同类型的所有资源(虚拟对象)的名称。
然后,应用程序可以通过调用类对象上的 instantiate() 方法来创建对象,即这些类的实例,并为新创建的对象起一个 32 位的名称。因此,每个应用程序的接口仅限于 4B 个对象。然后,应用程序可以选择()已命名的对象,如果转换表中没有该对象的条目,则会导致中断,以便资源管理器创建一个条目。每个 FIFO 的 64K 字节地址空间被划分为 8 个 8K 的 “子区域”。应用程序可以在每个子区域中选择()一个对象,因此一次可以对 8 个对象进行操作。对每个子区域的后续写入都被解释为对所选对象的方法调用,8 千字节空间内每个子区域基点的偏移字指定了方法,数据则是方法的参数。因此,接口支持每个对象的 2048 种不同方法。
通过这种方式,我们确保设备物理资源的所有知识都包含在资源管理器中。正是资源管理器实现了 CLASS 类及其实例。因此,资源管理器可以控制哪些 CLASS 类实例(虚拟对象类型)由硬件实现,哪些由资源管理器中的软件实现。资源管理器的代码可以存储在设备 PCI 卡上的只读存储器中,从而将设备与其资源管理器紧密联系在一起。电路板驱动程序唯一需要做的就是将设备的中断路由到资源管理器。
应用程序所能做的只是调用虚拟对象的方法,其重要性在于应用程序无法知道该对象是在硬件中实现的,还是在资源管理器的软件中实现的。在任何时候都能灵活地做出决定是一个巨大的优势。正如 Kim 引用 Michael Hara 所说的那样
这是这个星球上最聪明的东西。这是我们的秘诀。如果我们错过了一项功能或一项功能被破坏了,我们可以把它放到资源管理器中,它就能正常工作”。
结论
正如你所看到的,NV1 与当今风险投资所钟爱的 “最小化可行产品 ”相去甚远。他们的想法是尽快将产品交到用户手中,然后根据用户的反馈进行快速迭代。但 Nvidia 的风险投资人给了我们时间来开发真正的芯片架构,是为了让 Nvidia 在第一款产品失败后,能够在第二款产品的基础上快速迭代。在图形芯片上进行快速迭代要求应用程序不了解连续芯片的硬件细节。
在我的职业生涯中,我有幸与技术超群的工程师共事。柯蒂斯-普里姆(Curtis Priem)是其中之一,其他还有詹姆斯-高斯林(James Gosling)、已故的比尔-香农(Bill Shannon)、史蒂夫-克莱曼(Steve Kleiman)和吉姆-盖茨(Jim Gettys)。搜索结果显示,我和 Curtis Priem 都是 2 项 Sun 专利和 19 项 Nvidia 专利的发明人。在 Nvidia 专利中,柯蒂斯是 9 项专利的主要发明人,我是其余专利的主要发明人。大部分专利描述了 Nvidia 架构的部分内容,将柯蒂斯对硬件的卓越理解与我对操作系统的理解相结合,重新定义了 I/O 的工作方式。我认为这个架构是我职业生涯中最好的工程。当然,这也是对我影响最大的一次。谢谢你,柯蒂斯!
本文文字及图片出自 The Dawn Of Nvidia's Technology
共有 37 条讨论
发表回复
你也许感兴趣的:
- 【外评】英伟达™(NVIDIA®)开放式 GPU Linux 内核驱动程序即将成为“图灵”及将来 GPU 的默认设置
- 台积电押注非正统光学技术
- RockyLinux 在 RL10 中正式支持 RISC-V!
- felix86:在 RISC-V Linux 上运行 x86-64 程序
- 30年前的预言成真:RISC架构将改变一切
- 【外评】在 RiSC-V 上运行《巫师 3》游戏
- 【外评】英特尔称第 13 代和第 14 代移动 CPU 正在崩溃
- 【外评】英特尔酷睿 i9 CPU 死机问题看起来比我们想象的还要严重
- 【外评】Linus Torvalds 称 RISC-V 将重蹈 Arm 和 x86 的覆辙
- 谷歌扶持鸿蒙上位?










那是在 CPU 与图形设备的通信方式尚未标准化的时期。三角形还是四边形?共享内存还是命令队列?是 CPU 端 DMA 还是图形设备端?图形是 CPU/内存系统的一部分,还是显示系统的一部分?GPU 能否导致由虚拟内存系统提供服务的页面故障?
现在我们有了 Vulkan。Vulkan 规范了一些事情,但由于硬件设计决策会在 Vulkan 接口上暴露出来,因此有大量的选择。你可以通过 DMA 或共享内存将数据从 CPU 传输到 GPU。内存可以映射为双向传输,也可以映射为任一方向的单向传输。这种传输比普通内存访问要慢。由于 GPU 内存已满,您可以要求 GPU 从 CPU 内存中读取纹理,这也会带来性能损失。您也可以使用 “集成显卡 ”机器,CPU 和 GPU 共享同一内存。大多数硬件都提供了部分选项,但并非全部。
这就是为什么很多东西仍然使用 OpenGL 的原因,因为 OpenGL 隐藏了所有这些选项。
(我曾花了几年时间为现在最好被遗忘的设备编写 AutoCAD 驱动程序,后来又在 20 世纪 90 年代尝试让 3D 图形在 PC 上运行。我看到了很多最好被遗忘的图形卡)。
这是早期 2D 显卡的进化,在早期的 2D 显卡中,CPU 可寻址的帧缓冲器和各种 I/O 端口可能混合在一起,用于在文本和光栅图形之间切换模式、调整 DAC 中的视频模式、调整调色板查找表、为文本模式加载字体,还可能寻址一些 2D 协处理器,用于 “blitting”(有点像矩形 2D DMA)、线条绘制,甚至是一些基本的多边形渲染,以及抖动或点状着色等有趣的选项……
从历史的角度来看,这种由参与其中的关键人物所做的回顾是非常宝贵的。我认为,听到有关背景、假设、思维过程、内部争论、技术限制、商业现实甚至愚蠢运气的第一手资料,不仅能让我们了解我们是如何走到这一步的,还能让我们了解如何做得更好(甚至更好)。
虽然记忆犹新时的细枝末节的回忆可能很吸引人,但我特别欣赏几十年后写下的反思,因为这可以让我们对关键决策的结果有一个正确的认识,而且由于减少了对业务和个人的关注,一般来说可以进行更坦率的评估。
我也对此感到兴奋,但标题中出现一个品牌有点令人担忧。ATI、英特尔、AMD、苹果、IBM、Game Gaggle 等公司都不乏采访对象。事实上,NVIDIA 能在其他公司失败的情况下取得成功,很大程度上是运气使然。
> 很大程度上是运气的产物。
我不同意 “很大程度上 ”这个说法。运气总是商业成功的一个因素,当然也有一些值得注意的例子,运气可以说是一个足够大的因素,以至于 “很大程度上 ”可以适用–比如 Broadcast.com 在 .com 泡沫的顶峰时出售给雅虎。但是,我不知道有什么证据能证明运气是 NVidia 成功的一个重要因素,而不是对每个企业来说都是不变的环境因素。运气就像竞技航海中的风,它影响着每个人,有时是积极的,有时是消极的。
要取得并长期保持巨大成功,需要做出正确的选择和一流的执行力。关键是要持续不断地重复做这些事情,这样才能存活足够长的时间,让好运和厄运相互抵消。英伟达拥有 30 多年的历史,经历了多次行业性的繁荣、衰退和基本技术转型–这是一个持续取得巨大成功的一贯记录,以至于运气不可能成为一个重要因素。
尽管如此,在我看来,这篇文章并没有试图解释英伟达的长期商业成功。它关注的是早期做出的几个关键架构决定,这些决定可以说是相当冒险的,因为它们可能会在最终并不重要的功能上浪费大量的开发时间。然而,这些决定最终都得到了回报,对我来说,有价值的见解是,团队的主要成员与他们的竞争对手有着不同的背景,他们在多用户、多任务、虚拟化小型机和大型机架构方面的经验使他们相信,桌面架构迟早会朝着这个方向发展。这就好比 “滑冰要滑到冰球要去的地方,而不是它在的地方”。在快速发展的技术环境中,如果团队在相关领域既有广度又有深度的经验,就能大大提高做出此类预测的能力。
我想说,Nvidia 的 Cg 语言让开发人员更喜欢他们的硬件。
我记得大约在 2010 年或 2011 年,在圣何塞的一次会议招待会上(一定是 FAST,鉴于他参与了 LOCKSS 的工作,这也说得通),我坐在大卫-罗森塔尔(David Rosenthal)旁边,当时我并不知道他是谁。他向我解释了他在英伟达所做的一些创新,这些创新是为了让硬件更加模块化,让并行团队更容易工作,我们还聊到了我听到的关于 SUN 考虑授权 Amiga 硬件的传言,他证实了这一传言,但表示这不是个好主意,因为该硬件不支持地址空间保护。我想当时我对他和英伟达公司的了解还不够,所以印象不够深刻,但他是一个非常友好和朴实的人。
> 应用程序所能做的只是调用虚拟对象的方法……应用程序无法知道该对象是在硬件中实现的,还是在资源管理器的软件中实现的。随时做出决定的灵活性是一个巨大的优势。正如 Kim 引用 Michael Hara 所说的那样
> 这是我们的秘密武器。这是我们的秘诀。如果我们漏掉了一个功能或一个功能被破坏了,我们可以把它放到资源管理器中,它就会工作。
绝对精彩。了解技术的优缺点(缓慢/可更新的软件与快速/冻结的硬件),然后设计产品,这样就不会因为错过最后期限而导致公司倒闭。这就是精通技术的管理和巧妙的工程设计的完美组合。
我曾想买一块 Voodoo 显卡,但由于 PCI 版本不兼容,只好换回一块 Riva TNT。
当时我很后悔没能留住 Voodoo,因为我根本不知道它会变成什么样。
我们认为你要对 Voodoo3/4/5 的最终失败和 Nvidia 的统治负全部责任。
对不起…. 🙂
我当时用的是 Riva TNT,而朋友的 Voodoo… 2? Voodoo 2 可能真的是当时更好的 GPU。后来的游戏需要更后的 API(旧显卡不支持)和更高的性能,所以寿命并不长。
> 在 PC 内存最大为 640 兆的时代、
很确定作者的意思是写 640 千字节。
很难准确判断作者所指的时间段。NV1 于 95 年发布,当时新电脑的内存容量在 8-16 MB 之间并不罕见(我的 486 电脑在 94 年时内存容量已达 16 MB)。特别是如果你打算用它来玩游戏的话。
该句和该段明确指出这是兆字节而不是千字节
在 PC 内存最大容量为 640 兆字节时,PCI 总线可以寻址 4 千兆字节,这意味着它的地址位有很多是多余的。因此,我们决定将其中一些作为数据使用,以增加每个总线周期的数据传输量。NV1 使用了 23 个地址位,占总空间的 1/512。23 个地址位中的 7 个选择了 128 个虚拟 FIFO 中的一个,允许 128 个不同进程共享硬件访问权限。我们认为 128 个进程已经足够了。
好吧,但 “640 ”这个数字完全是虚构的。
PC 内存几乎都是以 2 的幂级数出售的。因此,你可以拥有 1MiB、2MiB、4、8、16MiB 容量的 SIMM。你通常可以混合搭配这些内存模块,有些 PC 有 2 个插槽,有些有 4 个,有些有不同数量的插槽。
因此,如果你认为 4 个插槽可以容纳某种最大容量,我们认为 64MiB 是消费类 PC 的常见最大容量,可能是 2×32 或 4x16MiB。很多人都遇到过这种限制。
如果从数学角度考虑,640MiB 是一个荒谬的数字。如何分割?如果安装了 4 个 SIMM,那么每个 SIMM 的容量就是 160MiB?根本不存在这样的硬件。据我所知,单个 SIMM 的最大容量通常为 64MiB,从物理上讲,不可能制造出比这更大的 “怪兽内存模块”。
此外,64MiB 需要 26 位地址位,而 640MiB 则需要总线上的 30 位地址位。如果一台假设的 PC 有 640MiB 的操作系统,那么地址总线上只有 2 个引脚未使用!这显然与他们所说的能够 “借用 ”更多引脚的说法不符!
这显然是个错别字,我推断作者本意是写 “64 兆字节”,但出于习惯或夸张,多加了一个零。
你直接错了。我做的第一台电脑是奔腾 2 RivaTNT,它有 640 MB 内存。
我找不到购买收据或具体的板卡品牌,但它有四个 SDRAM 插槽,我将其填充为 2×64 和 2×256。
编辑:在我的一些旧文件中找到了它:
我错了!不是四个 DIMM 插槽……是三个!其中一个肯定是 128,另外两个是 256。
这篇文章有点混乱,但我很确定我同意他们指的是原始 PC 架构的 640 千字节限制。奔腾 II 可以追溯到 1997 年,NV1 可以追溯到 1995 年,而拥有高达 32 位的新 PCI 总线可以追溯到 1992 年。640MiB 在推出时已经是一个巨大的内存容量了。
我不认为地址总线与 640KiB 或 640MiB 之间有任何数学关系,这只是当时人们认为 4GiB 寻址量有多大的锚点。
文章接着说,NV1 使用了 23 位地址总线,但在下一段中又补充说,还有 16 位用于数据。我不太明白这个计算方法。
实际上,我真的很难理解这种方案是如何运作的。它强烈暗示了开放寻址,没有其他 MMIO 设备与之冲突,但我认为 PCI 不是这样工作的。也许了解更多的人能解释给我听。
我的理解是,640MiB 被视为一种特殊的上限,在 1995 年不太可能被突破,在相当长的一段时间内,地址总线的很多位都留给了 NV1。640 KiB 似乎绝对不是一个上限,因为即使是 1984 年发布的 IBM PC/AT,其上限也是 16MiB。因此,作为 NV1 的设计者,你在设计该方案时不能假定 640KB 是 1995 年 PC 的某种上限。至于为什么是 640MiB,而不是其他,我相信 Windows 95 理论上可以处理 2GB 的数据,但在 512MiB 左右就会开始变得不稳定,所以他可能选择了 640MiB。
整件事有点讽刺,因为比尔-盖茨曾煞费苦心地说,他从未说过 640KB 是你所需要的全部(或类似的话)。鉴于我举的 IBM PC/AT 的例子,在 1995 年,人们对上限的理解肯定是不一致的,不管是不是伪造的。
是的,我不知道。除了对 1995 年来说是个很大的数字外,地址空间的东西,如果从表面价值来看,意味着你只需要敲掉 3 个比特就可以开始蚕食它。耸耸肩
令人印象深刻的构造,使用 4x ATA 驱动器启动时可能听起来非常狂野!
哦,天哪,Abit 主板!这让我想起了过去。这在什么年代花了多少钱?估计是 90 年代末吧。
那好吧!谦虚地说,我纠正了自己未经调查就妄加猜测的错误做法。看起来 640MiB 是完全可以实现的配置,尤其是 2×256+2×64 或类似配置。我必须说,这是一个巨大的内存容量。比任何视频游戏在硬件要求中规定的都要多。在那个时代,什么情况下可以用掉 640MiB,我就不知道了!
不过,我还是有点不明白为什么会硬性规定上限。难道这些主板阻止用户安装 4x256MiB 的 DRAM,以获得 1GiB 的内存?难道操作系统在寻址或使用这些内存时遇到了困难?640MiB 并不是我在 20 世纪 90 年代末所熟悉的那种数学上的最大值。4GiB 显然是 32 位地址总线的上限……再者,如果安装了 640MiB,那么总线上就只有 2 个空闲位了。
因此,我对文章中放弃这个数字还是有点好奇。如果能提供更多信息,将对我有所启发!谢谢你纠正我的错误!难怪会被降权!
我当时做了很多媒体和软件开发的工作,所以内存对我帮助很大。为什么是 640?不确定。我的那块板子可以达到 768。我在谷歌上搜索了一下,发现有些板卡的最大内存为 1GB。
那是计算机领域一个奇怪的时代。电脑的速度越来越快,容量也越来越大(没过多少年,我就做了一块主频为 2.8 GHz 的双插槽至强电脑,而在那之前,我哥哥做了一块主频为 700 MHz 的双插槽 P3 电脑),但所有的扩展板都是特殊用途的。我记得当时我特意挑了一块有 7 个扩展槽的板子。
但我觉得你关于作者为什么说 640 的问题是公平的!也许他们当时就有一台像我这样的机器。或者是英伟达在设计时就考虑到了这一点?
也许他们是这么想的,但任何与 PCI 总线配合使用的设计都是在 PC 能够使用比它更大的内存之后才推出的。
非常精彩的故事,谢谢你的分享!图形编程是广泛采用面向对象编程的主要推动力,在这种情况下对设备的抽象确实非常优雅。
这就像许多工程奇迹故事(如贝尔实验室、施乐公司)中的一个故事,革命性的技术是由(a)有足够 “自由 ”时间的聪明工程师和(b)周围没有愚蠢的管理者共同创造的。
你可以从《Unix 史》(Kernighans History of Unix)一书中读到,真正优秀的管理者–“开明的管理者”(IRC)–参与其中,而且不仅仅是参与其中,他们中的一些人绝对是关键人物,否则 Unix 就不会存在。这并不是说只要放任几个大脑袋,事情就能解决得很好。事实并非如此。
我读到这里就不读了:
> 因为 Nvidia 成为了世界上最有价值的公司之一,现在有两本书在解释它的崛起,并赞美黄仁勋的天才、
是啊,他真是个天才。(讽刺)。他是个做记号的人,这个人背后没有天才。
事实上,Nvidia 利用其市场地位对行业造成危害,强迫合作伙伴服从自己的命令,这使得这家公司和其他公司一样成为问题。他们的运作方式与其他掠夺性公司无异。
> 他是个做标记的人、
你错了。他曾在 AMD 担任设计工程师,后来去了 LSI 逻辑公司,帮助客户开发定制的 ASIC。他的一个大客户是 Sun 公司,帮助他们开发 SPARC 处理器和 GX 图形芯片,毫无疑问还有其他许多客户。
1989-1991 年间,我在 LSI Logic 做了三个 ASIC,詹森是后两个项目的联络人。他非常聪明、勤奋、技术知识渊博、和蔼、有耐心,尽管工作很忙,他还是很慷慨。
市场营销方面的东西是后来才出现的(或者说得更好些:它是潜在的,后来才出现的)
可能读过剩下的部分?我没有在这位关键工程师讨论细节和原理的任何专利上看到詹森的名字,我觉得这些名字都是刻意列出的。
Erik Lindholm(现已退休)关于 Riva 128 和许多其他早期 Nvidia 显卡的演讲:https://ubc.ca.panopto.com/Panopto/Pages/Viewer.aspx?id=880a…
我还有一块 NV1 显卡。
我也是,我也有一块 rendition verite 显卡,我想在某些方面它是第一块真正完全可编程的消费级 Gpu,因为它有一个 Risc 处理器。
我还有一块更老的 NEC ISA 显卡,带有 TI TMS34010 芯片 [1],是可编程 CPU/GPU。
[1] https://en.wikipedia.org/wiki/TMS34010
未提及 SGI。
我认为 SGI 与 Nvidia 的联系是在 DSHR 时代之后。