技术探讨StackOverflow的标签引擎
我第一次听说Stack Overflow的标签引擎之殇是在我读到他们和.NET垃圾收集器搏斗的故事的时候。如果你从来没听过的话,我建议你先读一下前面链接中的文章,然后再看看这篇有意思的的技术债务案例分析。

我第一次听说Stack Overflow的标签引擎之殇是在我读到他们和.NET垃圾收集器搏斗的故事的时候。如果你从来没听过的话,我建议你先读一下前面链接中的文章,然后再看看这篇有意思的的技术债务案例分析。
但是只要你上过Stack Overflow,你一定用过这个功能,而且用的时候可能都没意识到它的存在。它的能力主要通过 stackoverflow.com/questions/tagged 这样的 url 体现出来的【译者注:比如要找带java标签的问题,url就是https://stackoverflow.com/questions/tagged/java】,当你找到所有带.NET、C#或者Java标签的问题时,你可以看到下面这样的页面(注意右边栏中,相关标签已经被选中了)。
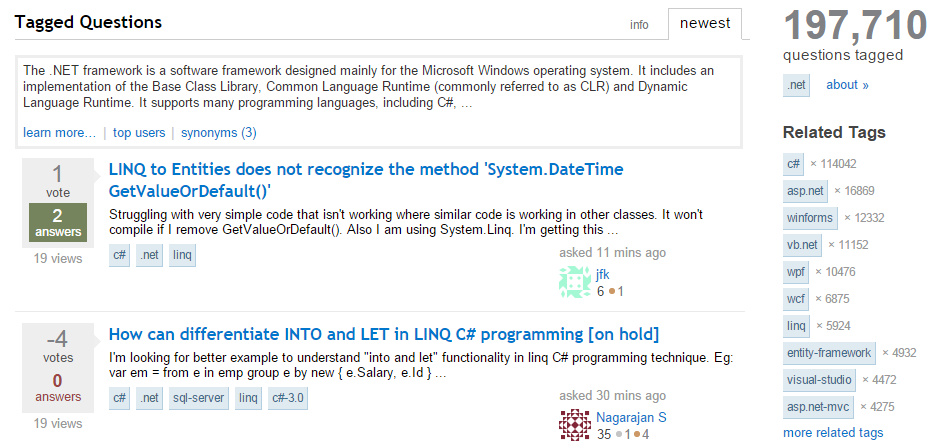
标签API
和简单的搜索一样,你可以很轻松的通过一些复杂的查询语句来找到你想要的结果(有些复杂查询你需要你先登录stackoverflow),比如你可以搜索:
像上面这样的搜索一般和你个人偏好没有任何关系。但是如果你希望默认屏蔽带某些标签的问题时,可以在登录后到你的账户管理页面,点击 Preferences 菜单,就可以在页面底部看到忽略标签列表。有时候,站里的一些牛人设置了100多个忽略标签,像这种情况,要处理这些和个人设置相关的搜索时,要解决的问题就不是那么简单了。【译者注:现在stackoverflow登录后,点击头像进入账户管理页面,然后有个 Settings 按钮(找不到可以Ctrl+F一下),然后就可以看到Preference了】
获取公开的提问数据
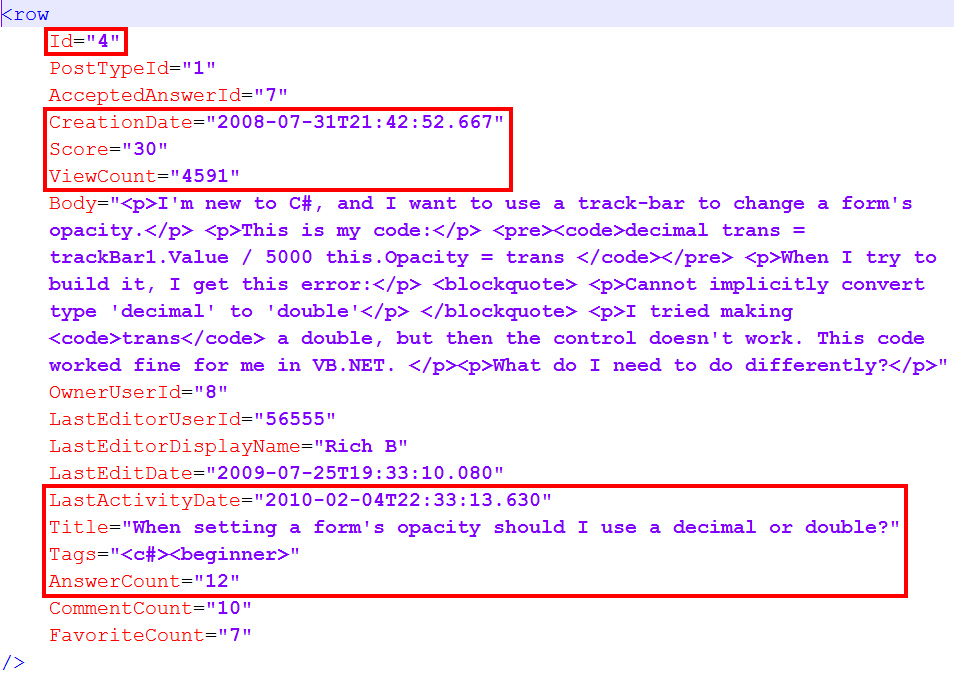
正像我说的那样,如果要建立一套标签引擎,我想应该先看一下它会处理处理哪些数据【译者注:额,原作者之前真的没有说过,他给出的链接里也没有说过,大家看看就好】。幸运的是,我们可以从这里下载到所有的Stack Exchange站点的数据【译者注:stackoverflow和stackexchange关系参考这里】。为了简化问题,只管第一次发布的内容(不包括编辑历史),我下载了stackoverflow.com-Posts.7z(高能预警,这个文件有5.7GB),这个压缩包中最新数据是到2014年9月份的。简单描述一下这份数据长什么样子的吧,一个典型的问题长得就像下面这个xml文件的样子。对于标签引擎,我们只需要关系红色框框住的部分即可,因为它只需要提供一个索引,所以它只需要关注meta-data,不需要关心问题的具体内容是什么。
下面是对下载的数据做了一些简单的的统计分析,可以看到,有超过7900万条问题,如果要把所有数据读取到List中,要消耗足足2GB的内存。
Took 00:00:31.623 to DE-serialise 7,990,787 Stack Overflow Questions,used 2136.50 MB Took 00:01:14.229 (74,229 ms) to group all the tags, used 2799.32 MB Took 00:00:34.148 (34,148 ms) to create all the "related" tags info, used 362.57 MB Took 00:01:31.662 (91,662 ms) to sort the 191,025 arrays After SETUP - Using 4536.21 MB of memory in total
一共花了31秒从磁盘上的文件反序列化(通过这个第三方库protobuf-net),然后又花了大约3.5分钟进行了处理和排序,最后我们大概用了4.5GB的内存空间,下面是一些统计信息:【译者注:原作者没提供预处理的源代码,这个效率相当给力啊】。
Max LastActivityDate 14/09/2014 03:07:29 Min LastActivityDate 18/08/2008 03:34:29 Max CreationDate 14/09/2014 03:06:45 Min CreationDate 31/07/2008 21:42:52 Max Score 8596 (Id 11227809) Min Score -147 Max ViewCount 1917888 (Id 184618) Min ViewCount 1 Max AnswerCount 518 (Id 184618) Min AnswerCount 0
结果真的很让人吃惊,stackoverflow上被查看最多的一个问题点击次数居然超过了190万次【译者注:这个问题现在点击次数已经达到234万次以上了】,这个问题已经被管理员锁定了,尽管该问题实际上没什么建设性,【译者注:因为stackoverflow的管理员认为这个问题具有历史意义,但是他们认为这个问题基本上没什么意义,所以也提醒不要提类似的问题】,该问题同样也是回答次数最多的问题,有518个回答。接下来,最让人惊叹的可能是获赞次数最多的问题,达到了惊人的8192次,该问题是“为何处理排序的数组比未排序的要快?”【译者注:这个问题现在获赞次数超过了14000次,最高票回答接近2万次zan了】。
创建索引
所谓索引长什么样子?简单说来,就是一堆经过排序的列表(List),列表中记录的是问题主表(List)中的偏移量,问题主表是持有所有Quesiton对象的。用下图可以说明索引:
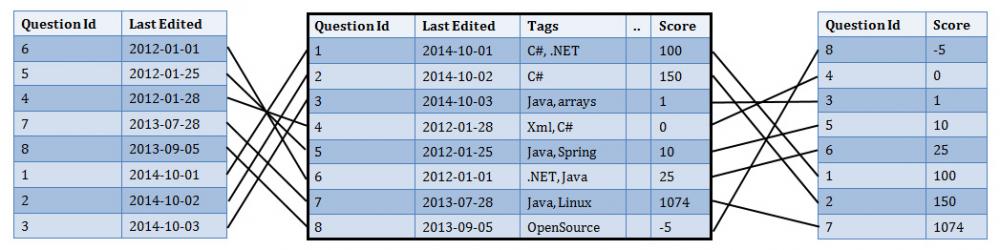
说明:这种组织方式非常类似于Lucene的索引结构【译者注:扫盲一下,这就是咱们大Java世界的Luncene】 从下面的代码看,创建索引这件事情也不是多复杂的事情:
// start with a copy of the main array, with Id's in order, { 0, 1, 2, 3, 4, 5, ..... }
tagsByLastActivityDate = new Dictionary<string, int[]>(groupedTags.Count);var byLastActivityDate = tag.Value.Positions.ToArray();
Array.Sort(byLastActivityDate, comparer.LastActivityDate);
同时,比较器的代码也很简单(注意一下,这里是对byLastActivityDate数组进行排序,不过是使用的quesiton数组中的数据来决定该数组中元素的位置的)
public int LastActivityDate(int x, int y){
if (questions[y].LastActivityDate == questions[x].LastActivityDate)
return CompareId(x, y);
// Compare LastActivityDate DESCENDING, i.e. most recent is first
return questions[y].LastActivityDate.CompareTo(questions[x].LastActivityDate);}
好了,一旦我们建立好了这些排序后的列表,如上图表示的那样(编辑时间从近到远,分数从低到高),我们可以很容易的从这两个数组中获取他们在问题主表Quesitons列表中的数据。举个例子,遍历Score数组(1,2,…,7,8),获取所有的Id,可以得到这样的数组{8,4,3,5,6,1,2,7},数组内容就是他们在主表Questions中的位置。下面的代码就是表述如何怎么查询的,同时考虑到了翻页的情况(pageSize和skip)。
var result = queryInfo[tag] .Skip(skip) .Take(pageSize) .Select(i => questions[i]) .ToList();
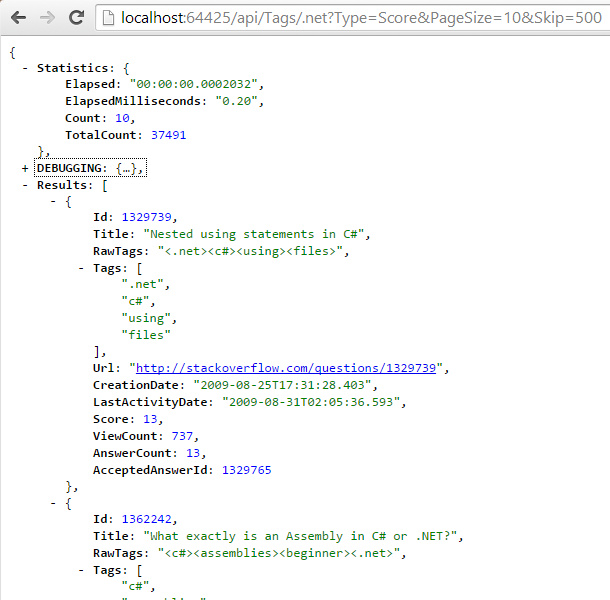
上面的工作搞定后,我就可以提供API,你可以通过浏览器来查询了。注意下图中的时间是在服务器处理的时间,事实上这个数字也是靠谱的,查询单个标签的速度非常非常快。
我已经将相关 资源 和之前发表的 演讲 的页面加到我的网站中了,如果你想了解更多,可以去看看。其中还有一篇我2014年我在伦敦NDC会议上发表的演讲视频:“性能也是一种特性”
要点回顾
这是介绍Stack Overflow标签引擎系列文章中的第二篇,如果之前没看过第一篇,建议您先阅读。
上一篇文章发布后,Stack Overflow公开了一个份非常漂亮的性能报告,里面有更多标签引擎的统计数据。从下图中,你可以看到他们把标签引擎部署在几台性能比较强悍的机器上(译者注:这个估计是以当年的标准算强悍),但实际上,CPU使用峰值只有10%,这意味着这套系统还有很大潜力,所以访问需求激增或者某天业务特别繁忙时,它依然hold的住。
设置忽略标签
在第一篇文章中,我只做了一些最简单的事情,比如查询带有某个特定标签的问题,还有一些多条件排序(根据分数,点击量等等)。但是事实上,标签引擎需要处理更多更复杂的事情,比如下面这位说的:
上图中这位想表达什么呢?他的重点是说我们做标签引擎时,任何时候要记住每个人都是可定制从搜索结果中排除哪些结果的,而且排除哪些是可以设置的,你可以在“忽略标签列表”中设置,比如你设置了某个忽略标签,那么当你搜索时,带这些标签的问题都不会出现在你的眼前。
注意:如果能让你知道有哪些问题因为你的偏好设置被隐藏了,这样用户体验会更好。一旦有搜索结果因为你的偏好设置被隐藏时,你可以看到如下的信息:(当然,也可以设置不要把问题隐藏起来,而将命中的问题标记成灰色):

正常情况下,绝大部分人应该只有很少的忽略标签,最多不会超过10个。但是这个世界总从不缺乏例外,和我接触过的一位Stack Overflow的深度用户,@leppia,分享了一下他设置的标签列表(译者注:我把这篇文章贴下来翻译时,看到足足14页长度,深深的以为被黄利民推荐的这篇文章给坑了,但是发现这个标签列表占了10页,oh,yeah…):
vb6 vba homework grails coldfusion flash iphone air sifr ms-access db2 vbscript perl sap jpa gql java-ee magento ipad qt weblogic blackberry gwt pentaho wordpress mac corba intellij-idea lucene
点击这里下载完整的标签列表。
你可能要花很大功夫才能看完整个标签列表,为了节省时间,下面列出了一些统计数据:
- 这份清单有3753个标签,其中210个带有通配符(比如cocoa*, *hibernate*这样的)
- 这些标签和通配符展开以后,总共会生成7677个标签(整个stack overflow大概有30529个标签)(译者注:这是写这篇文章时的数字)
- 有6428251个问题至少命中这7677个标签中的一个!
通配符
如果你想感受一下使用通配符过滤,你可以访问下面的url:
- *java*
- [facebook-javascript-sdk] [java] [java.util.scanner] [java-7] [java-8] [javabeans] [javac] [javadoc] [java-ee] [java-ee-6] [javafx] [javafx-2] [javafx-8] [java-io] [javamail] [java-me] [javascript] [javascript-events] [javascript-objects] [java-web-start]
- .net*
- [.net] [.net-1.0] [.net-1.1] [.net-2.0] [.net-3.0] [.net-3.5] [.net-4.0] [.net-4.5] [.net-4.5.2] [.net-4.6] [.net-assembly] [.net-cf-3.5] [.net-client-profile] [.net-core] [.net-framework-version] [.net-micro-framework] [.net-reflector] [.net-remoting] [.net-security] [.nettiers]
一种简单的处理方法就像下面代码中描述的那样,具体说来就是遍历所有的通配符标签,然后将每个通配符标签和所有标签比对,看看是否匹配。(Is ActualMatch(…)方法是个简单的字符串匹配函数,其实StartsWith,EndsWith或者Contains更加合适一些。(译者注:原作者是用VB.net写的,所以这里给的是三个方法是MSDN上的方法介绍,用来判断一个字符串是不是以某个字符串开头、结尾,或者包含某个字符串)。
var expandedTags = new HashSet();
foreach (var wildcard in wildcardsToExpand){
if (IsWildCard(tagToExpand)) {
var rawTagPattern = tagToExpand.Replace("*", "");
foreach (var tag in allTags) {
if (IsActualMatch(tag, tagToExpand, rawTagPattern)) expandedTags.Add(tag);
}
} else if (allTags.ContainsKey(tagToExpand)) {
expandedTags.Add(tagToExpand);
}
}
上面的代码在带有通配符标签较少的时候工作的很好,但是效率上不是很尽如人意。其实32000个标签,相对来说并不是很多,但即使这样,当wildcardsToExpand中含有210个元素时,都需要处理1秒钟了。在Twitter上和几个Stack overflow的员工聊过以后,他们认为,如果标签引擎的一次查询要超过500毫秒的话,就太慢了,所以,如果要花1秒钟来处理带有通配符的标签的话,是一件不能忍的事情。(译者注:上面代码其实是做了一个双重循环,将所有匹配通配符的标签都拎出来,效率应该是O(mn),当m和n都不是很小的时候,显然有必要优化)
Trigram Index
(译者注:我不知道该如何准确、专业地翻译Trigram Index这个专业术语。。。) 那我们可以做的更好么?其实正好有一项技术可以完美的解决这个问题,“使用Trigram Index进行正则表达式匹配”,这个技术也被用在Google Code的搜索功能中。我不会在这里详细的解释此技术,想要了解更多,可以看一下前面链接中的文章,那里面已经写得非常详尽了。简单说起来,就是你需要为标签建立一个倒排索引,然后再来对这个索引进行搜索。这样带有通配符的标签数量就不会造成多大的影响,因为你已经不需要对整个标签列表做遍历了。
所谓Trigram,就是先标签将被分成3个字母一组的片段,比如javascript这个标签,将被划分为如下片段:(’_’用来表示开头和结尾)
_ja, jav, ava, vas, asc, scr, cri, rip, ipt, pt_
接下来,把所有标签都分成这样的3个字母的片段后,再对这样的片段建立索引,同时标记它们在标签中出现的位置,这样后面可以回溯:
- _ja -> { 0, 5, 6 }
- jav -> { 0, 5, 12 }
- ava -> { 0, 5, 6 }
- va_ -> { 0, 5, 11, 13 }
- _ne -> { 1, 10, 12 }
- net -> { 1, 10, 12, 15 }
- …
举个例子,如果你想要匹配所有包含java的标签,比如*java*,你可以找到jav和ava的索引值,假设从上面列出的片段列表中,会检索出2个匹配的元素:
- jav -> { 0, 5, 12 }
- ava -> { 0, 5, 6 }
现在你可以知道只有所有带有0和5索引有可能匹配的,因为它们都包含jav和ava,(索引中有6和12的不行,因为它们并不同时包含这两个片段)
译者注:原作者的描述的确让人非常难以理解,很显然这种翻译类型文章也不适合我来写大量篇幅的介绍性文字,尽量用3句话说明:Trigram Index就是先将所有tag打个编号,比如0=java,1=xxx, 2=yyy,…,5=javascript, 6=jaxb, …12=javseen, 这样0和5都包含_ja, jav, ava,所以_ja,jav和ava索引中都带有{0, 5};
接下来,*java*是想要找到所有带有java的标签,*表示非空字符的话,这样的标签必须同时包含jav和ava两个片段,因为分3个连续字母片段时已经在jav和ava的索引中记录下来包含这样标签的索引了,所以直接先找jav的索引,有0,5,12号标签,然后再找到ava索引中有0,5,6号,很显然,只有0号和5号标签可能包含java,6号和12号不可能包含java;这样一下子将搜索范围缩减到了2个,最后还需要做一下简单的模式匹配即可,因为有可能字符串这样的:javbcdeava
结论
下面是该算法在我的笔记本电脑上的运算结果,其中Contains方法是上面那个最原始的双重循环算法,Regex方法是希望优化速度,把正则表达式先编译一下(事实上,这样效率更差)
Expanded to 7,677 tags (Contains), took 721.51 ms Expanded to 7,677 tags (Regex), took 1,218.69 ms Expanded to 7,677 tags (Trigrams), took 54.21 ms
正如你所看到的这样,基于Trigram的倒排索引完胜。如果你感兴趣的话,请到Github上查看源代码。
本文主要介绍了一种可以被标签引擎用来实现通配符查询的方法,因为我不在Stack Overflow工作,所以他们是不是采用同样的方法,我不得而知,但至少我这个方法效率还是相当不错的。
下一步讨论内容
我们取得了阶段性成果,但是想要做好标签引擎,还有很多事情需要考虑:
- 复杂的布尔查询,比如带有这样的标签:“c# OR .NET”, “.net AND (NOT jquery)”,不仅要能实现,效率还要很高才行
- 针对标签服务的DDOS攻击
在十月份,我们收到大量的精心构造的请求,导致我们的标签引擎服务器资源使用率飙升,不过这正好是我们将高效的标签引擎发挥用途的地方。(译者注:这是引用stack exchange网站中的一段话)
这是讨论如何实现 Stack Overflow 标签引擎系列的第三部分,如果之前没看过第一篇和第二篇的话,建议先阅读一下前两篇。
复杂的布尔查询
Stack Overflow的标签引擎有个强大的功能,它允许用户使用多个标签组合出非常复杂的查询,比如:
一个简单的实现方法就像下面代码中那样,使用一个HashSet.aspx)来高效的判断某个问题应该被包含在搜索结果内,还是被排除在搜索结果之外。
var result = new List(pageSize);
var andHashSet = new HastSet(queryInfo[tag2]);
foreach (var id in queryInfo[tag1]){
if (result.Count >= pageSize)
break;
baseQueryCounter++;
if (questions[id].Tags.Any(t => tagsToExclude.Contains(t)))
{
excludedCounter++;
}
else if (andHashSet.Remove(item))
{
if (itemsSkipped >= skip)
result.Add(questions[item]);
else
itemsSkipped++;
}
}
我们面临的最主要问题是需要对所有带有tag1标签的问题遍历一次,直到我们找到足够一页的匹配结果,就是foreach (var id in queryInfo[tag1])这段循环里的代码;另外我们还要将所有带有tag2标签的问题初始化到HashSet中,这样我们才能检查是否匹配。这种方法的缺点是,当skip变量很大,或者需要排除的标签列表tagsToExclude很长的时候(比如“忽略标签”),这个方法就需要更长的时间。请查看本系列第二篇了解更多“忽略标签”的情况。
位图索引(Bitmaps)
那么我们能做的更好吗?答案当然是肯定的,正好有种机制非常适合做这种查询,它的名字就是:位图索引。想要用这种技术,需要做一些预计算,将匹配和不匹配的信息存储在bit位中,匹配设置为1,不匹配设置为0。在我们的使用场景中,想要的效果大概是下图中这样的【译者注:下图是对第一篇的图增加了扩展,建议看一下第一篇】:
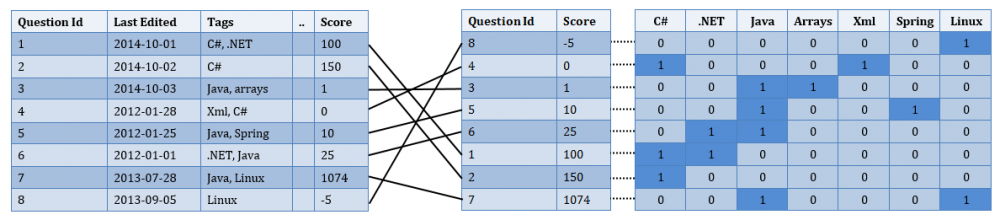
接下来,要做的就是对这些bit位做操作了(真实代码只能以字节为单位来操作),比如你想要找到带C#和Java标签的问题,代码大概是这样的:
for (int i = 0; i < numBits / 8; i++){
result[i] = bitSetCSharp[i] & bitSetJava[i];
}
这个方法最大的缺点是我们必须要针对每种排序规则(比如按评论时间排序,按创建时间排序,按分数排序,按查看次数排序,按回答数量排序)给每个标签创建位图索引(C#, .NET, Java等等),因此需要消耗很大的内存空间。拿Stack Overflow 2014年9月份的数据来看,当时大概有800万个问题,每8个问题用一个字节,一个位图大概占976KB或记为0.95MB。总共加起来需要的内存达到惊人的149GB(0.95MB*32000个标签*5种排序)。
压缩位图
幸运的是有种叫做“游程编码”的技术可以大幅压缩位图【译者注:游程编码是一种无损压缩算法,基本原理是用某种符号或者串长来替代具有相同值的连续符号】,我在这里使用了出色的EWAH库的C#版本,这个开发库是基于Daniel Lemire等人发表的论文《 Sorting improves word-aligned bitmap indexes 》。使用EWAH的最大好处是你在做bit位操作的时候不用自己去解压缩位图,它会在适当的时候自己完成(想要知道如何做到的,可以看一下我在github上对AndNot方法做的这次提交)。
如果你不想读这篇学术论文,下图展示了如何将位图压缩成64bit位长的word的,这些位图的特点是有1个或者多个bit被设置为1,接着又是多个连续的0. 因此下图中31 0x00的意思是将31个64bit的word(所有bit位都被设置为0)表示成单个值,而不是31个word。

【译者注:上图中是一种典型的位图索引方法,即使用串长替代真实串的方法,具体的意思是这个位图首先是0个64bit的word,接下来是1个不全是0的64bit的word,这个word的值是17,2 bits set意思是这64位的信息里有2个1;接下来是31_64个的连续0,然后是1个不全是0的64bit的word,具体值是2的41次方。依次类推,凡是出现n 0x00的地方,都表示连续的n_64个0,这样只需要用一个数字加上0x00即可表示n*64bit长度的数据】
为了能直观的说明能节省多少空间,下表列出了有不同位数置为1时,使用压缩位图算法所占用的大小,单位是字节。(为了对比,一个未压缩的位图有100万字节,或者0.95MB)
| # Bits Set | Size in Bytes |
| 1 | 24 |
| 10 | 168 |
| 25 | 408 |
| 50 | 808 |
| 100 | 1,608 |
| 200 | 3,208 |
| 400 | 6,408 |
| 800 | 12,808 |
| 1,600 | 25,608 |
| 3,200 | 512,008 |
| 6,400 | 1,000,008 |
| 128,000 | 1,000,008 |
正如你所看到的这样,我们只需要64,000个bit位即可表达出一个正常位图(准确的说,只需要62,016个bit位)。注意:我做这些测试的时候,置为1的bit位的位置在800万个数据样本中是均匀分布的。压缩效果也是要看具体压缩数据的情况的,像这种均匀分布的情况是不利于压缩的。如果连续相同的bit位越集中,压缩效果越好。
整个Stack Overflow 3万2千个标签的数据,使用压缩位图的方法,将内存使用量降低到了1.17GB, 而未压缩前需要用149GB,效果是相当令人印象深刻的。
结论
使用压缩位图实现的查询比朴素的使用HashSet的常规查询方法(见上面代码)要更快,事实上这两种方法其实都不赖,但是在某些情况下,效果区别还是很大的。
如下图所示,在做AND NOT查询时,使用压缩位图的方法快出许多,即使是最不利于压缩的情况下,常规方法耗时超过150毫秒,而压缩位图方法只需要大约5毫秒(图中x轴是需要排除忽略的问题数量,y轴是消耗时间,时间单位是毫秒)
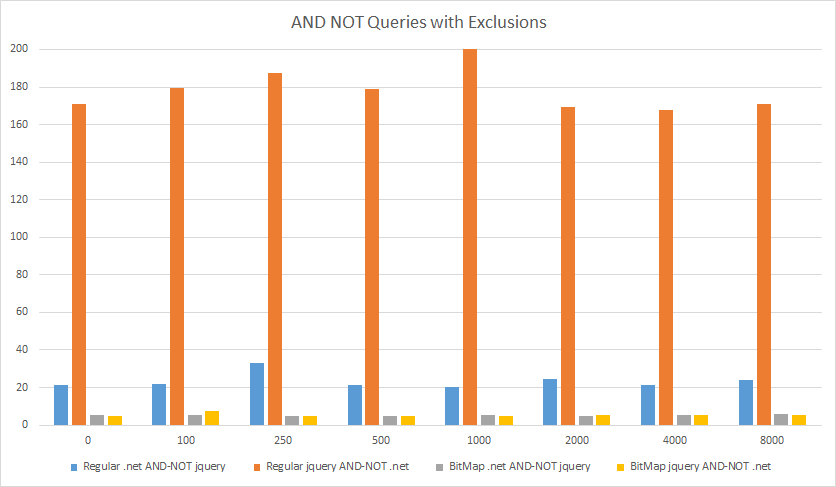
测试样本中有194,384个问题带有.net标签,528,490个问题带有jquery标签。
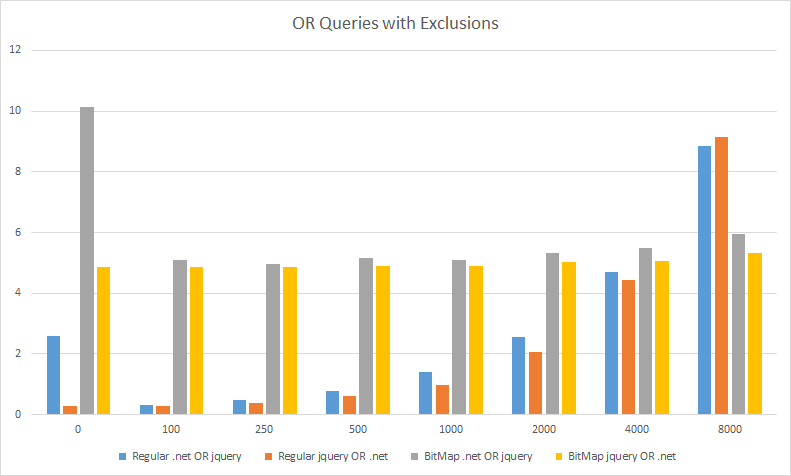
为了体现本人严明公正的高贵品格,我必须要申明,使用压缩位图方法在做OR查询时要比常规方法慢,具体数据如下图所示。但是需要注意数据范围,相比常规查询方法也就是5毫秒和1~2毫秒的差距,因此压缩位图算法依然是非常快的!但是压缩位图算法还有个优势就是不管要排除的问题数量有多少,它用的时间都差不多,而常规方法下,随着需要排除忽略的问题数量增加,速度变得更慢。
如果你对所有查询类型的结果感兴趣,可以点击下面的链接查看:
深入阅读
- 位图索引
- 位图索引的神话
- Roaring Bitmaps (一种更新的、更快速的压缩位图方法)
- 什么情况下位图索引会比整数列表快
- 位图索引在数据库中的应用
- 一些黑客们对Roaring Bitmaps的讨论
- 不同位图索引的实现研究
- 实战
- Github是如何通过位图索引快速复制仓库的
- Roaring Bitmap在Elastic Search中的使用【译者注:Elastic Search是一个搜索引擎,我没研究过,看来这个搜索引擎背后的技术也是位图索引】
- 位图索引在Lucene中的应用【译者注:Lucene是注明的Java全文检索引擎工具包】
- 压缩位图在Druid中的应用【译者注:Druid是一种分布式大数据实时处理系统】
内容预告
【译者注:尽管原作者有预告,但是他真的没接着写了,不是我懒没翻译。。。】
还有很多东西要去做,接下来我讨论下面的话题:
- 到目前为止,我的实现方法还没有对垃圾收集器做一些调优,而且我的方法真的做了很多很多内存分配的事情。Stack Overflow在如何与.NET垃圾收集做斗争中提到“no-allocation”原则,我打算也尝试一下。
【译者注:上图中的Tweeter中说Stack Overflow的用户非常多,导致很多次垃圾回收(频繁的垃圾回收会降低系统性能)】
在十月份,我们收到大量的精心构造的请求,导致我们的标签引擎服务器资源使用率飙升,不过这正好是我们将高效的标签引擎发挥用途的地方。

本文由 TecHug 分享,英文原文及文中图片来自 伯乐在线。

共有{1}条精彩评论