如果您使用 Python… 你现在就需要了解这 3 个工具!
2025 年,一些库/框架已成为使用 Python 开发人员的 “瑞士军刀 ”的一部分,尤其是如果您的目标是构建高效、健壮的应用程序。在本文中,您将发现今年需要掌握的 3 个基本工具,并附有实际示例,以便您可以立即开始使用它们!

Python 仍然是软件开发中最通用的语言之一。
2025 年,一些库/框架已成为使用 Python 开发人员的 “瑞士军刀 ”的一部分,尤其是如果您的目标是构建高效、健壮的应用程序。
在本文中,您将发现今年需要掌握的 3 个基本工具,并附有实际示例,以便您可以立即开始使用它们!
1 – 快速应用程序接口
FastAPI 是用 Python 构建 REST API 最高效的框架之一。它旨在提供高性能,可与其他框架一较高下(在此基准中搜索 FastAPI),并提供 OpenAPI 文档和异步处理等多种便利。
此外,FastAPI 还是 Flask 的直接竞争对手,在本文中,您可以看到它们之间的主要优缺点和差异。下面简要介绍了 FastAPI 相对于 Flask 的一些优势:
| 特点 | Flask | FastAPI |
| 性能 | 低(单线程) | 高(异步,基于 Starlette) |
| Typing Support | Not native | 是的,利用现代 Python 功能 |
| 数据验证 | 需要额外的库 | 本地使用 Pydantic |
| 自动文档 | 需要额外设置 | 自动生成 OpenAPI 文档 |
安装
要安装 FastAPI,只需运行以下命令:
pip install "fastapi[standard]"示例
使用此框架启动并运行 API 的最小代码是创建一个名为 fastapi_example.py 的文件,其中包含以下代码:
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}请注意,在函数定义 (def) 前面,我们使用了 async 关键字,这使得该函数的处理是异步的。使用这一功能其实很简单,它能让你的代码比 Flask 更快。
现在,要运行代码,需要使用以下命令:
fastapi dev fastapi_example.py该命令的结构如下:fastapi dev <python_file_name>。 如果创建了名为 app.py 的文件,则应运行该命令:
fastapi dev app.py要测试 API 是否正常工作,请执行此命令:
curl --location 'http://localhost:8000'这样,您应该会收到一个包含以下内容的 JSON:
{"Hello": "World"}2 – Pydantic
在使用应用程序接口时,必须确保接收和发送的数据正确无误。
Pydantic 通过提供基于 “静态类型 ”的验证系统,有效地解决了这一问题。通过该库,您可以定义自动验证输入的数据模型,在出现错误时生成错误,甚至提高代码的可读性。
从根本上说,该库可以防止由于赋值不当而导致的运行时错误:
class User:
name: str
u = User()
u.name = None # <-- It should not be possible to assign the value 'None' to the type str. This is possible due to Python's dynamic typing.
print(u.name.upper()) # <-- Generates an error because u.Name assumes the value None. None does not have the attribute
"""
ERROR!
Traceback (most recent call last):
File "<main.py>", line 7, in <module>
AttributeError: 'NoneType' object has no attribute 'upper'
"""Pydantic 也用于 FastAPI,因此当您使用 Pydantic 定义模型时,FastAPI 会自动验证输入数据并生成 OpenAPI 文档。
不过,Pydantic 的使用并不局限于 FastAPI。您可以在代码的任何地方使用它,以确保数据模型/类在程序执行过程中保持一致,从而使您的代码更加健壮。
安装
要安装 Pydantic,只需运行以下命令即可:
pip install pydantic示例
运行 Pydantic 的最小代码示例是
from datetime import datetime
from pydantic import BaseModel, PositiveInt, ValidationError
class User(BaseModel):
id: int
name: str = "John Doe"
signup_ts: datetime | None
tastes: dict[str, PositiveInt]
external_data = {
"id": 123,
"signup_ts": "2019-06-01 12:22",
"tastes": {
"wine": 9,
b"cheese": 7,
"cabbage": "1",
},
}
user = User(**external_data)
print("---------------- Success ----------------")
print(user.id)
print(user.model_dump())
incorrect_external_data = {"id": "not an int", "tastes": {}}
try:
User(**incorrect_external_data)
except ValidationError as e:
print("---------------- Error ----------------")
print(e.errors())在这段代码中,我们将看到这样的输出:
---------------- Success ----------------
123
{'id': 123, 'name': 'John Doe', 'signup_ts': datetime.datetime(2019, 6, 1, 12, 22), 'tastes': {'wine': 9, 'cheese': 7, 'cabbage': 1}}
---------------- Error ----------------
[{'type': 'int_parsing', 'loc': ('id',), 'msg': 'Input should be a valid integer, unable to parse string as an integer', 'input': 'not an int', 'url': 'https://errors.pydantic.dev/2.10/v/int_parsing'}, {'type': 'missing', 'loc': ('signup_ts',), 'msg': 'Field required', 'input': {'id': 'not an int', 'tastes': {}}, 'url': 'https://errors.pydantic.dev/2.10/v/missing'}]注意到 incorrect_external_data 变量中的 id 属性是字符串而不是整数,这就是模型验证失败引发异常的原因。
使用 FastAPI 的示例
下面是一个使用 Pydantic 接收用户数据并自动验证信息的 API 示例:
from datetime import datetime
from typing import Optional
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, PositiveInt
class User(BaseModel):
id: Optional[PositiveInt] = None
name: str = "John Doe"
signup_ts: datetime | None
tastes: dict[str, PositiveInt]
app = FastAPI()
users: dict[int, User] = {}
@app.post("/users")
async def insert_user(user: User):
id = len(users) + 1
user.id = id
users[id] = user
return {"id": user.id}
@app.get("/users/{user_id}")
async def read_users(user_id: int):
try:
user = users[user_id]
return user
except KeyError:
raise HTTPException(status_code=404, detail="user not found")运行此命令可将用户插入 API:
curl --location 'http://localhost:8000/users' \
--header 'Content-Type: application/json' \
--data '{
"signup_ts": "2025-02-14 12:22",
"name": "Test User",
"tastes": {
"wine": 9,
"cheese": 7,
"cabbage": 1
}
}'此命令将返回包含插入用户 ID 的 JSON 文件:
{"id": 1}现在,只需运行下面的命令就能获取插入的用户:
curl --location 'http://localhost:8000/users/1'现在,神奇的一幕出现了! 当运行此命令时,如果 name 属性不是字符串,则会自动进行模型验证,并返回错误信息:
curl --location 'http://localhost:8000/users' \
--header 'Content-Type: application/json' \
--data '{
"signup_ts": "2025-02-14 12:22",
"name": 1,
"tastes": {
"wine": 9,
"cheese": 7,
"cabbage": 1
}
}'返回错误响应,包含验证详细信息:
{
"detail": [
{
"type": "string_type",
"loc": [
"body",
"name"
],
"msg": "Input should be a valid string",
"input": 1
}
]
}Pydantic 使结构化数据的处理变得更加简单,与 FastAPI 结合使用时,可让您在创纪录的时间内构建可靠的 API。
不要忘记使用 Pydantic 验证代码中的其他模型!
3 – Polars
从事数据科学工作的朋友们,我没有忘记你们!当我们谈论 Python 中的数据操作时,首先想到的库通常是 Pandas(著名的 import pandas as pd)。然而,随着数据集的增长,Pandas 可能会成为性能瓶颈。这就是 Polars 脱颖而出的原因。
Polars 是一个优化的数据处理库,其设计目的是利用并行处理和优化技术实现极高的速度和效率。它采用基于列的结构,类似于 Apache Arrow,因此非常适合在不影响性能的情况下处理大量数据。
它的亮点之一是可以使用 GPU 使处理速度更快:
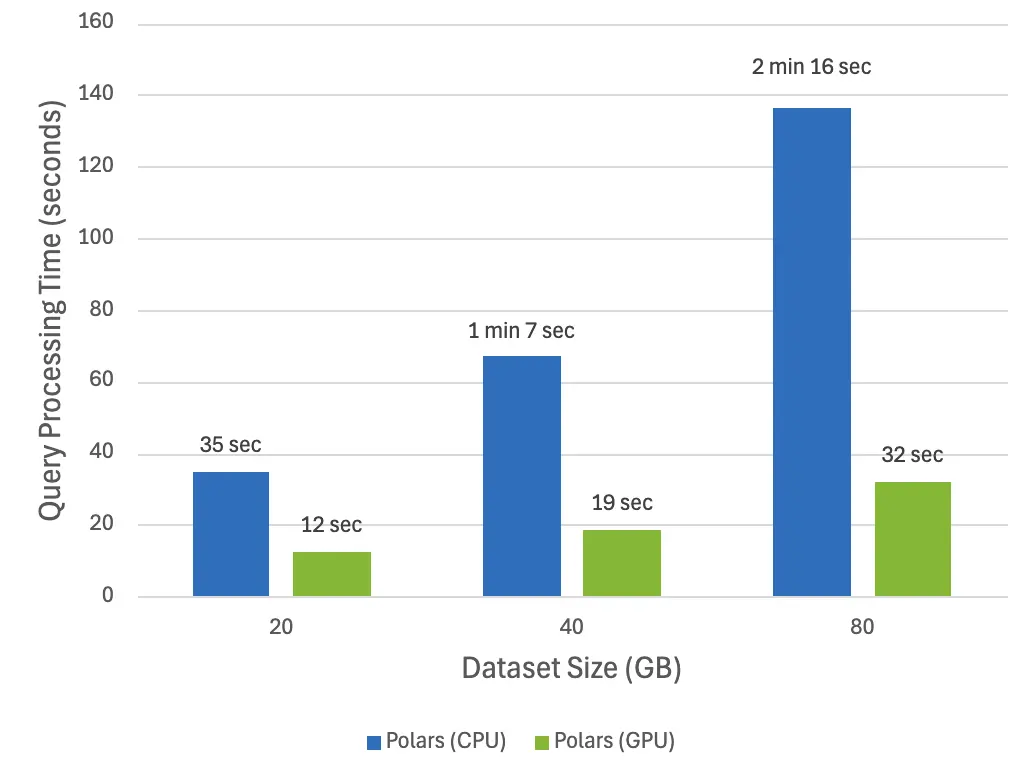
为什么使用 Polars 而不是 Pandas?这里有几个原因:
- 更快: 由于采用了并行处理,对大型数据集的操作速度明显更快。
- 内存消耗更少: 列式架构减少了内存使用量。
- 直观的 API: 提供与 Pandas 类似的语法,但有所改进。
- 支持懒惰评估: 允许以优化的方式执行操作,只处理必要的数据。
安装
要安装 Polars,只需运行以下命令即可:
pip install polars要安装在 GPU 上运行的版本,我建议在 Python 3.11 中使用,因为在 3.13 中我遇到了一些依赖兼容性问题。
pip install polars cudf-polars-cu12不过,我会留下一份链接列表,这些链接可能会对您使用 GPU 运行 Polars 有所帮助:
- Polars page for GPU installation
- Installation of Cuda in Ubuntu 24.04
- Nvidia-SMI documentation (For video card monitoring)
示例
首先,下载最常用的数据集 Iris:https://github.com/pola-rs/polars/blob/main/docs/assets/data/iris.csv。
然后,以 iris.csv 为名将其保存在与你的 PYTHON 文件相同的目录下。
import polars as pl
q = (
pl.scan_csv("iris.csv")
.filter(pl.col("sepal_length") > 5)
.group_by("species")
.agg(pl.all().sum())
)
df = q.collect()示例–Polars vs Pandas
如果您仍然怀疑 Polars 无法打败 Pandas,那么我决定做一个测试,对两者进行比较。为此,需要从以下网站下载一个稍大的 CSV 文件(约 500 MB),即 5m Sales Records 文件:https://excelbianalytics.com/wp/downloads-18-sample-csv-files-data-sets-for-testing-sales/。
然后,需要安装 pandas:
pip install pandas然后运行这段代码:
import time
import pandas as pd
import polars as pl
csv_file = "5m Sales Records.csv"
group_by_column = "Region"
sort_column = "Unit Price"
def measure_time(func, *args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
return result, end - start
def pandas_test():
df = pd.read_csv(csv_file)
df_filtered = df[df[sort_column] > 30]
df_grouped = df.groupby(group_by_column).agg({sort_column: "sum"})
df_sorted = df.sort_values(by=sort_column, ascending=False)
df_sorted.to_csv("output_pandas.csv", index=False)
def polars_test():
df = pl.read_csv(csv_file)
df_filtered = df.filter(df[sort_column] > 30)
df_grouped = df.group_by(group_by_column).agg(pl.col(sort_column).sum())
df_sorted = df.sort(sort_column, descending=True)
df_sorted.write_csv("output_polars.csv")
_, polars_time = measure_time(polars_test)
print(f"Polars: {polars_time:.4f} secs")
_, pandas_time = measure_time(pandas_test)
print(f"Pandas: {pandas_time:.4f} secs")该代码将对数据集进行一系列简短的处理(过滤、用总和聚合分组、排序),最后将数据集保存到一个新的 CSV 文件中,并在终端中打印执行时间。
运行该代码后,可以得到以下结果:
Polars: 2.4661 secs
Pandas: 33.0203 secs注:处理时间可能因执行环境而异。
你可以得出自己的结论,但我会在下一个数据科学项目中给 Polars 一个机会。
结论
在 2025 年学习并掌握这三个库将加速你的开发,使你成为更高效的程序员。FastAPI 和 Pydantic 的组合对于构建健壮的 API 尤为强大,而 Polars 则是为那些需要性能而又不放弃使用 Python 的人量身打造的。
如果您想了解更多类似内容,请继续关注我们的为文章,并与其他程序员小伙伴们分享!

你也许感兴趣的:
- Python 3.15 的 Windows x86-64 解释器有望提升 15% 运行速度
- 讨论:为什么Python能胜出?
- Python中的“冻结”字典
- Python的起源
- Reddit将评论后端从Python迁移至Go语言
- 首次探秘 Django 的新后台任务框架
- await 并非上下文切换:解析 Python 协程与任务的本质差异
- Python并非数据科学领域的理想语言(第二部分):语言特性
- Python并非数据科学领域的理想语言(第一部分):亲身经历
- 10 个提升 Python 代码运行速度的智能技巧

你对本文的反应是: