
你知道谁在五月份通过放弃微服务转而采用单体架构?答案并非资金紧张的初创公司或独立项目——正是 亚马逊自身 ,为其Prime Video服务做出的决策。这个靠销售微服务基础设施每年赚取数十亿美元的AWS,竟承认有时老派的单体架构更胜一筹。
这家几乎撰写了分布式系统教科书的公司突然转变立场,在云原生社区引发震动。亚马逊后来删除了原始博文,但互联网从不忘却——后续内容将揭示这一点。
过去五六年间,我始终反对不必要或过早采用微服务架构。亚马逊Prime Video回归单体架构后,我发现多位知名架构师也开始反对将微服务作为默认选择。

然而在多数技术圈,微服务仍被奉为构建现代软件的唯一途径。它主宰着技术大会、博客和招聘启事。团队采用它的原因并非需求所迫,而是因其看似理所当然(且能提升简历分量)。“云原生”已与“默认微服务”划上等号,仿佛其他方案都已如软盘般过时。
微服务确实能解决实际问题,但前提是规模足够庞大。而多数团队根本不具备这种规模。
本文旨在促使大家重新思考行业已鲜少探讨的问题: 微服务是否应成为大规模构建的默认选择? 我们将剖析转型案例,借鉴资深架构师的洞见,权衡取舍与替代方案。综合考量后,您才能判断自身问题是否真需依赖微服务群集。
微服务:敏捷性与复杂性的权衡
纸面上,微服务令人心驰神往。将应用拆解为众多小型服务,每个服务可采用任意语言编写,由小型团队独立维护,并按各自时间表部署。当需要扩容时,仅需扩展承载负载的部分。其承诺如此优雅:独立部署能力、自主团队、多语言栈支持、弹性扩展。
但问题在于:每次拆分都会产生接缝,而每个接缝都是潜在的故障点。在单体架构中,函数调用瞬时可控;跨服务调用则转化为网络请求:速度变慢、易出错,有时还会返回不一致的数据。当服务数量达到数十(甚至数百)个时,仅为维持系统运行就需要版本管理、模式演进、分布式事务、追踪系统、集中日志记录以及重型CI/CD管道。
这张Gartner图表精准揭示了这种权衡:微服务以单一代码库的简洁性,换取了多代码库的复杂性。
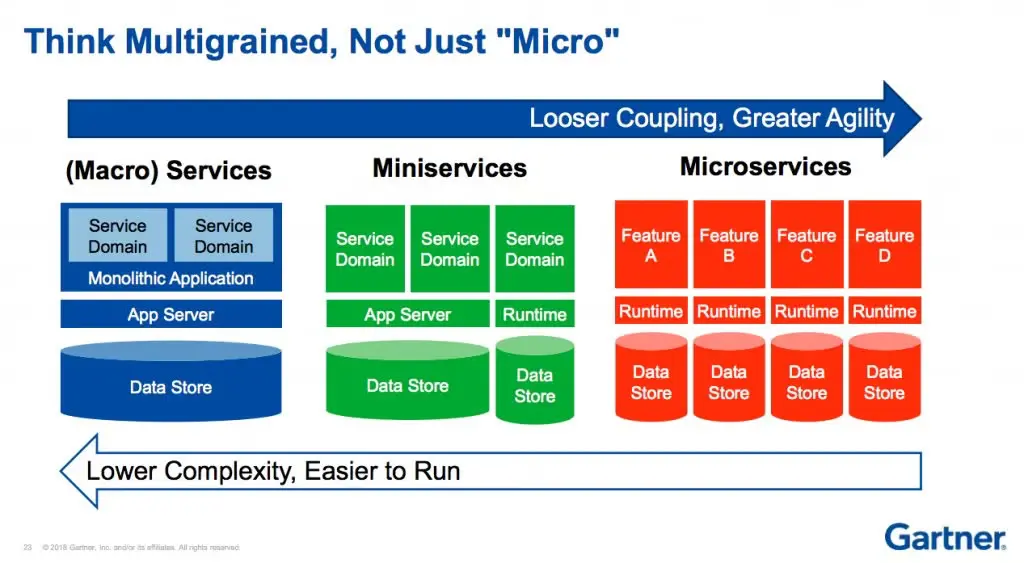
在超大规模场景(如Netflix)中,这种权衡或许值得。但当运营收益无法抵消成本时,团队最终将为调试、协调和粘合代码付出高昂代价,仅为维持产品运转。
微服务仅在特定场景下具有合理性——即当独立业务能力需要独立扩展和部署时。例如, 支付处理 (安全关键型,更新频率低)与 推荐引擎 (内存密集型,持续进行A/B测试)存在根本差异。这些组件具有不同的扩展模式、部署周期和风险特征,因此需要独立服务支撑。
微服务能否成功取决于业务领域边界是否清晰,且与团队结构相匹配——正如康威定律所预言。若组织能自然划分为拥有独立能力的自主团队,微服务便可能奏效。(因此多数 “一个半披萨”规模的初创公司 并不适用,对吧?)
这正是微服务在亚马逊、优步等企业中行之有效的原因——尽管 并非总是如此 。
事实上,多数组织缺乏必要条件:专属服务所有权、成熟的CI/CD流程、强大的监控体系,以及至关重要的 足以支撑运营开销的规模 。过早采用微服务的初创企业往往后悔自己的决定。
所以请自问:
您是在用微服务解决独立的扩展问题,还是在为解决方案增添不必要的复杂性?
微服务的大逆转
讽刺的是,尽管科技巨头最有可能从微服务中获益,但正是这些公司正在逐步放弃微服务架构,其结果令人瞠目。
亚马逊Prime Video:单体架构实现90%成本削减
2023年5月,亚马逊工程师承认了不可思议的事实:Prime Video已放弃微服务转而采用单体架构。其视频质量分析(VQA)团队曾构建出教科书般的分布式系统:通过AWS Step Functions和Lambda监控数千条视频流,所有组件独立且可扩展。理论上堪称无服务器架构的完美典范。
实践中却酿成灾难。“我们意识到分布式架构在特定场景下收益甚微,”Marcin Kolny在现已存档的Prime Video工程博客中写道。由于编排开销过高,这个“无限可扩展”的系统 在仅承受预期负载5%时就崩溃了 。
解决方案简单得令人尴尬:将所有组件合并为单一进程。此举最终实现了 成本降低90%且性能显著提升 。
Twilio Segment:从140个服务到单一高效整体架构
2018年,客户数据平台Twilio Segment在坦诚的博文《告别微服务》中记录了类似的逆转历程。
其系统曾膨胀至140余个服务,导致运维陷入混乱。曾有段时间,三名全职工程师耗费大部分时间处理突发故障而非开发新功能。正如他们所言:“微服务架构非但未能提升效率,反而让小团队深陷复杂性爆炸的泥潭。原本的核心优势反成沉重负担。随着开发速度骤降,缺陷率却呈爆炸式增长。”
他们的解决方案极具颠覆性却卓有成效:将全部140余个服务整合为单一整体。成效立竿见影。原本耗时一小时的测试套件,现在仅需几毫秒即可完成。开发者生产力大幅提升:一年内对共享库进行了46次改进,而微服务时代仅有32次。
Shopify:理性胜于炒作
Shopify运营着全球最大的Ruby on Rails代码库之一(超过280万行代码)。他们没有追逐微服务,而是刻意选择模块化单体架构:通过清晰划分组件边界实现单一代码库。
Shopify工程师认为“微服务会带来新的挑战”,因此选择了无需额外运维开销的模块化方案。
所有这些案例都引出了一个问题:
既然连微服务先驱都在退缩,我们为何仍将其奉若圭臬?
专家之声:警惕微服务狂热
软件架构领域最受尊敬的权威人士——那些打造出众多备受推崇系统的幕后推手——同样对微服务提出警示,并反复强调他们在大规模实践中目睹的错误。(毕竟啦啦队员不会上场,云端开发关系人员鲜少参与大规模构建。)
Rails 创始人:简约胜于复杂
Ruby on Rails 创建者David Heinemeier Hansson(简称DHH)长期倡导以简约性超越架构潮流。他在对亚马逊Prime视频战略逆转的分析中直言不讳:
“所有这些理论的实际效果终于显现,实践证明微服务或许是让系统不必要复杂化的最大诱惑。”
DHH用“诱惑之歌”的比喻恰如其分:微服务承诺优雅,却让团队在复杂性的礁石上撞得粉碎。
微服务:本世纪的十年错误?
GitHub前首席技术官Jason Warner对微服务毫不留情地评价道:
“我确信过去十年最大的架构错误之一就是全面采用微服务。”
沃纳深谙规模之道:GitHub以互联网级规模运行,他曾领导Heroku和Canonical的工程团队。其批判更具穿透力,因其源于实践经验:
“全球90%的企业其实只需运行一个单体应用,对接主数据库集群及其备份,辅以缓存和代理系统即可。”
GraphQL联合创始人直言:“别这么做”
还有GraphQL的联合创始人Nick Schrock。若有人有理由为分布式系统喝彩,那必定是他。然而他却表示:
“微服务本质上是个灾难性的糟糕主意,未来将涌现大批市值数十亿美元的公司,它们的存在意义仅在于修复微服务造成的破坏。”

他进一步将微服务描述为组织性赌博:
“你最终得到的是一堆必须永久维护的服务,它们完全契合五年前的组织架构和产品需求。而如今,这些服务已毫无意义。”
这位亲手打造分布式系统修复工具的专家直言 除非万不得已,否则不要采用分布式架构 ——或许是时候认真倾听了。
质疑微服务极端主义的其他声音
其他工程领导者也开始重新审视微服务极端主义。
优步的Gergely Orosz坦言:
**”我们正将大量微服务迁移至宏服务(规模适中的服务)。正是因为测试和维护数千个微服务不仅困难重重——从长远来看,它带来的麻烦甚至可能超过短期解决的问题。”
优步仍在合理场景下运行微服务,但他们正选择性地投入精力。
以Kubernetes和谷歌云贡献闻名的Kelsey Hightower用CS101原理戳穿微服务神话:
“我敢打赌,单体架构的性能将超越所有微服务架构。只需计算服务间网络延迟,以及每次请求所需的序列化与反序列化操作量。”
尽管他随后删除了这条推文,但网络计算逻辑依然给微服务打出了低分。
当这些先驱者——包括真正解决大规模分布式系统难题的专家——开始敲响警钟时,值得我们认真审视。
我的核心质疑是:
若GitHub首席技术官认为90%的企业无需微服务,你确定自家属于那10%?
微服务的隐性成本
团队常低估这些隐性成本,正是微服务需要如此谨慎的原因。
运维成本
单体架构很简单:进程内函数调用。
微服务则用网络架构取代。每个请求如今都要穿越多台机器,经过负载均衡器、服务网格和身份验证层,由此产生更多故障点和基础设施需求。你突然需要服务发现(服务间如何定位彼此)、分布式追踪(跨服务追踪请求)、集中日志(聚合多服务日志)以及能理解服务拓扑的监控系统。
这些组件虽各司其职,但组合后却形成复杂昂贵的体系。数据冗余导致存储成本攀升,持续的服务间调用累积网络出口费用,云成本增长速度远超应用本身。Prime Video的工作流中,服务间S3数据传输的协调成本甚至超过实际处理开销。
开发者效率的枷锁
在微服务架构中,真正的难点不在于编写代码,而在于处理分布式系统的交互。
Stack Overflow在《微服务架构的宏观困境》中指出关键的生产力杀手:分布式状态迫使开发者编写防御性代码,不断检查局部故障。
在单体架构中,开发者可在单个仓库内端到端追踪代码路径。而在微服务架构中,单个功能可能横跨四个或五个仓库,涉及不同依赖关系和部署周期。添加一个字段就需要数周协调:更新服务后,还需等待消费者接入、版本化API、管理发布流程等。不同团队通常使用不同技术栈维护各自的微服务,这还存在意外破坏系统功能的风险。在单体架构中编译器能捕获的破坏性变更,如今却在生产环境中以运行时错误的形式暴露出来。
测试与部署复杂性
单体架构的集成测试和端到端测试因可在本地内存中运行而速度更快。分布式系统则无法享受这种便利:要获得真正可靠的验证,必须跨越众多服务边界进行集成测试和端到端测试。因此这些测试速度更慢、更脆弱,且需要与生产环境相似的预发布环境,所有这些因素都使基础设施成本翻倍,并延缓了反馈循环。
许多团队直到测试套件成为瓶颈时才意识到这一点。部署编排又增添了新挑战。跨依赖服务的滚动更新需精心排序,以避免破坏契约。版本不兼容问题频发:服务A与B的v2.1版本兼容,却与v2.2版本冲突。
部署失败会导致系统部分更新,难以恢复。
数据管理与一致性
微服务最被低估的复杂性在于跨服务边界数据的一致性维护。
单体架构受益于ACID事务特性:操作要么完全成功,要么完全失败。而微服务将事务拆分到不同服务中,迫使开发者构建分布式Saga (带回滚逻辑的多步工作流),接受最终一致性(数据延迟后才正确),或编写补偿逻辑(额外代码用于撤销部分失败)。曾经单一的数据库事务,如今需跨越网络跳转、重试机制和部分失败场景。当状态在服务间重复存在时,调试不一致的订单或支付流程将变得极其困难。
正如研究证实,数据冗余、正确性挑战和事务复杂性是微服务系统中最突出的痛点。
复合效应
这些复杂性呈倍增态势:运维开销加剧调试难度,导致测试效率下降,进而使部署风险攀升,引发更多故障。微服务不仅将复杂性从代码转移到运维,更会侵蚀工程流程的每个环节。
除非业务规模迫使采用,否则这种代价往往超过收益。
试想:
若每次网络跳转都增加复杂度与成本,你的用例真的值得付出这个代价吗?
超越微服务:更智能的架构替代方案
在默认采用微服务前,值得考虑更简洁、结构良好的架构方案——它们能在避免分布式复杂性代价的前提下实现同等可扩展性。值得关注的替代方案包括模块化单体架构与面向服务架构。
模块化单体架构:结构化而不分散
不同于传统单体架构易陷入混乱的困境,模块化单体通过清晰的模块API和严格的职责分离实现内部边界管控。每个模块暴露明确界定的接口,使团队能独立协作,同时部署单一、统一的系统。
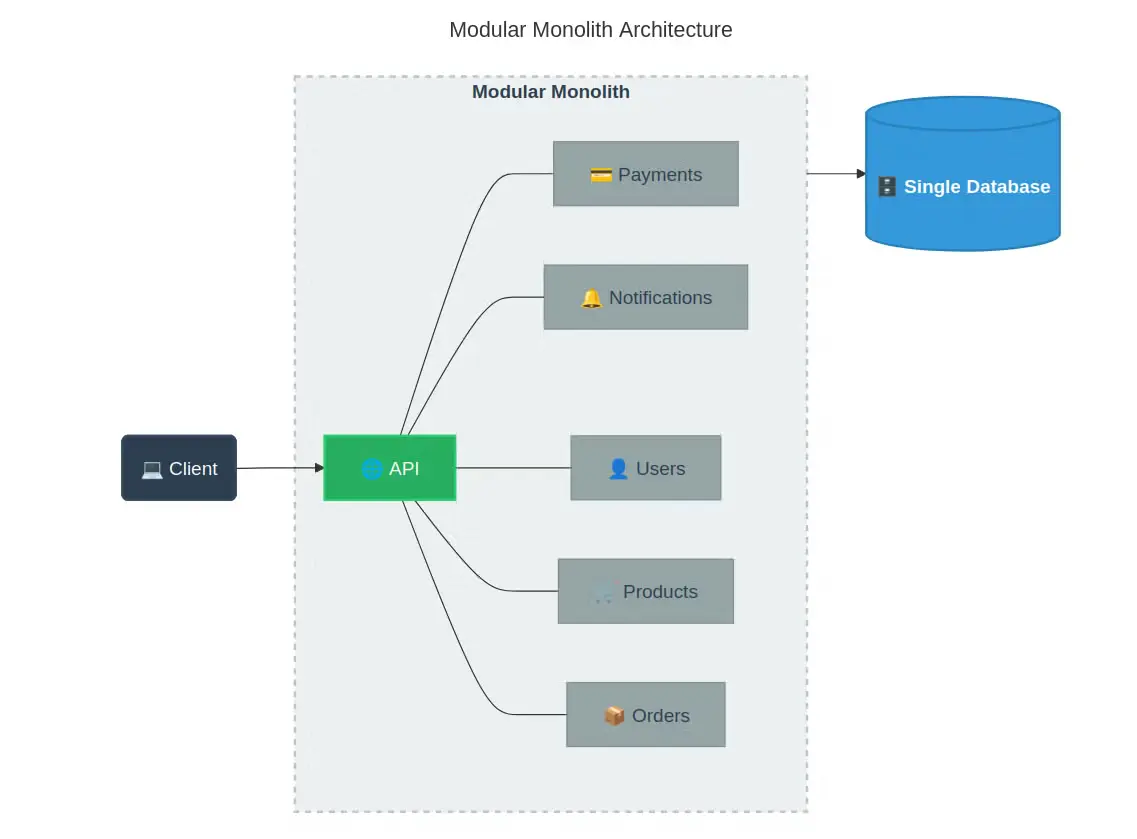
正如肯特·贝克在《单体→服务:理论与实践》中所阐述,模块化单体架构通过组织纪律而非分布式网络管理耦合关系。核心差异在于:模块间虽仍通过显式契约通信(如微服务),但采用快速可靠的函数调用替代易受网络延迟和部分故障影响的HTTP请求。
为何有效?
- 操作更简洁 :微服务级组织架构,单体架构的简洁性
- 一致性更强 :完整ACID事务支持
- 调试更轻松 :单一可追溯系统,无需在ELK草堆里找针
- 性能更优异 :函数调用胜过网络跳转
现实案例佐证:Shopify的280万行代码库每分钟处理30TB数据,不同团队负责独立模块,却能实现整体协同部署。Facebook的运作模式与此类似。(首席架构师Keith Adams开玩笑说,若想说服你放弃微服务,他就是最佳人选。)
随着Spring Modulith、Django、 Laravel和Rails等框架的近期发展 (如Shopify的大规模实践所示),模块化单体架构将在未来几年获得更广泛的应用。
面向服务的架构:中间地带
面向服务的架构(SOA) 介于单体架构与微服务之间,更倾向于构建大型领域驱动服务,而非数十或数百个微小服务。这些服务通常通过企业服务总线(ESB)进行通信,在保持关注点分离的同时降低协调开销。
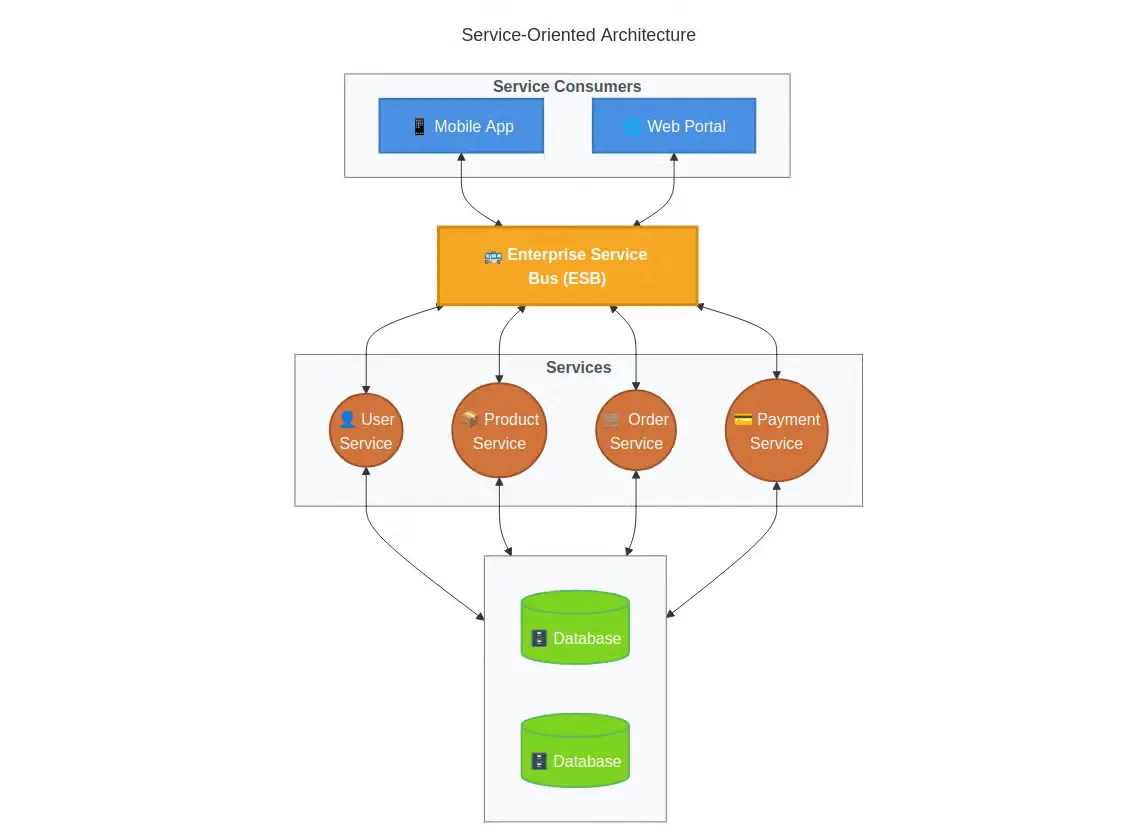
相较于将认证、用户偏好和通知拆分为独立微服务,SOA可将其整合为单一“用户服务”,在简化协调的同时保留服务自主性与精准扩展能力。SOA实现了企业级模块化,避免了超精细分布式架构的开销。
其有效性体现在:
- 适配边界 :减少冗余,构建领域对齐的服务
- 精准扩展 :按真实业务领域扩展服务
- 务实复杂度 :避免超精细粒度开销,保留模块化逻辑
SOA的大规模应用成效已获验证。欧洲第九大航空公司挪威航空采用SOA提升了复杂航班运营的敏捷性。瑞信集团的SOA部署早在2000年代初就支撑着每日数百万次的服务调用。
审慎抉择:务实胜于浮夸
架构设计应以解决实际问题为根本依据。
我在咨询中常举这个比喻: 切柠檬无需宝剑,普通刀具足矣。 正如古老智慧所言:简约乃至臻之境。
很可能,你并非谷歌(无需谷歌级容错能力),也非亚马逊(无需海量写入可用性),更非领英(每日不处理数十亿事件)。绝大多数应用程序都未达到这种规模,因此需要的解决方案与超分布式架构截然不同。
对于多数系统而言,结构良好的模块化单体架构(适用于包括初创企业在内的常见应用)或面向服务架构(适用于企业级应用),都能提供与微服务相当的可扩展性和弹性,且无需承担分布式架构的复杂性代价。另一种选择是采用适度规模的服务(即 宏服务 ,或Gartner提出的 微服务 )替代海量微服务。
值得思考的是:
若更简洁的架构能实现同等可扩展性,为何还要选择复杂的微服务?
Docker:适用于任何架构
Docker 不仅适用于微服务——它在各类架构中均表现卓越,包括单体架构、SOA、API及事件驱动系统。真正的价值在于:无论采用何种架构方案,Docker都能提供稳定性能、简化部署流程,并赋予应用灵活的扩展能力。
Docker能干净地封装应用程序,确保从笔记本到生产环境的配置一致性,简化依赖管理,并实现应用与主机系统的隔离。采用Docker化的单体架构可享受所有这些优势,同时避免微服务带来的编排开销。
微软关于容器化单体架构的指南明确指出:无论运行单个服务还是五十个服务,扩展容器都“远比部署额外虚拟机更快更简单”。Twilio Segment观察到,容器化单体架构能“通过启动更多容器实现环境的横向扩展,并在需求下降时关闭容器”。对多数应用而言,整体扩展正是所需方案。
在DevOps层面,基于Docker的单体架构比完整的微服务体系更易运维。当从格式统一的容器收集日志而非格式各异的分散服务时,日志聚合变得更为简便。监控与调试仍可集中管理,故障排查无需跨服务边界追踪请求。
因此值得认真考虑:
即便没有微服务的复杂性,Docker仍能提供相同优势——简洁部署、轻松扩展、一致环境。何不继续沿用?
总结
几年前,我当时8岁的儿子想要一辆自行车。他主要在公寓小区里骑车,偶尔会冒险驶入附近的小巷。他其实不需要21档变速系统,但那些闪闪发光的变速器让他着了迷——想象一下通过换挡就能骑得更快!他完全想要这件机械结构精妙的宝贝。(面对满眼星光的孩子……或者创业者,实在难以反驳:P)
新车刚骑上路,就出现变速打滑、链条卡死等问题,这辆自行车停修的时间比骑行时间还长。最终我们只能把它扔掉。
当时我未能说服他,其实简易自行车更适合他。但或许这篇文章能让某些制定架构决策的成年人醒悟。
我们技术人员总沉迷于复杂系统。(检查:你是否已在暗忖: 带变速器的自行车有什么复杂的?? )但活动部件越多,故障率就越高。复杂性往往制造的问题比解决的更多。
我的核心观点并非全盘否定微服务——而是要选择契合实际需求的架构,而非盲从云巨头推销的方案(他们自己正悄悄撤回 承诺 )。模块化单体架构或精心设计的SOA,往往更能满足需求并提升团队效率。
那么关键问题来了:
你是为云原生热潮而设计,还是为自身业务需求而设计?
你真的需要微服务吗?
本文文字及图片出自 You Want Microservices, But Do You Really Need Them?
我真的很想把这篇文章发给公司里所有开发者(我们这小公司才120多人,开发测试约40人),但公司已选定政治路线,新潮技术正让人们如痴如醉。
我们从事的物理仿真软件领域(以资深开发者和测试员的经验而言),根本不需要微服务拆分带来的复杂性与软件工程知识。
复杂性应控制在绝对必要的范围内,那句老话“保持简单,傻瓜”至今仍充满智慧。
既然方向已定,我将以个人贡献者的身份,全力为公司及合作客户竭尽所能。
若工作负载形态各异,微服务确有价值。
若非如此,尽可能坚持单体架构。
但若需处理需交接GPU的任务,直接为其创建独立服务即可。别再为微服务纠结了。
若团队超过百人且职责分散,不妨尝试微服务。否则继续单体架构也无妨。
若微服务薄如leftpad.js且仅承载单次RPC调用,或许不必实施。但若需独立缩略图服务或授权认证服务,这便是合理的边界划分。
这里不存在“万能解方”。
确实,这正是文章的核心观点:
>> 微服务仅适用于特定场景——当独立业务能力需要独立扩展和部署时。例如支付处理(安全关键、更新频率低)与推荐引擎(内存密集型、持续A/B测试)存在根本差异。这些组件具有不同的扩展模式、部署周期和风险特征,因此需要独立服务来支撑。
我好奇的是,服务达到什么规模才算微服务?通常主张的团队规模服务在我看来并不算“微”——但多数情况下确实是合适的规模。
“微服务”之所以得名,是因为“面向服务架构”在实践中逐渐变形——尤其在大众认知层面,人们因其演变为支持SOAP及WS-*系列集成标准的近乎单体架构而普遍排斥它。
后来微服务流行起来后,人们过度强调了“微”的字面意义,导致“微服务”开始遭到抵制——因为相关实践偏离了方向,重蹈了导致“SOA”被抛弃的覆辙。
我猜下一代架构应该叫“金发姑娘服务”。
说得对。若当初叫“多服务”或“团队划分应用”,恐怕不会如此风靡。
我所见过的定义标准是:团队(事后看来)能在两周内重构微服务。这听起来极端,但我认为一个月更合理。
微服务与其他架构的另一关键差异在于:每个微服务应能(临时)独立完成核心功能且不存在硬依赖,这意味着必须拥有所需数据的副本。面向服务架构并不具备此特性,因此我将其视为轻度分布式单体架构。“分布式单体”是对微服务集群最糟糕的称呼——既要承受所有痛点,却无所获。
在我看来这定义过于极端。
谷歌在推广微服务方法论方面发挥了重要作用。
我在谷歌任职期间,微服务通常由10-30人的团队耗时数年开发。虽然4-5人的小团队能启动服务,但要实现服务生产化并投入市场往往需要额外增员。
我感觉人们往往高估了微服务的规模,却低估了单仓库的庞大程度。十次中有九次,我所见到的所谓单仓库其实是针对 单个项目 而非跨项目的仓库。微服务亦是如此——亚马逊或谷歌视作微服务的东西,外界可能都当作单体架构看待。
Kubernetes是微服务架构的典范。其设计确保各微服务间以松耦合方式协作,避免过度依赖。
例如:API服务器仅负责读写etcd资源。独立的调度器微服务通过监视资源存储库与可用节点间的变化,实际执行Pod到节点的分配任务。而运行在每个节点上的另一微服务(称为kublet)则接收分配指令,启动(或关闭)分配到本节点的Pod。这些具体操作均由API服务器之外的组件完成。
你可以单独运行kublet,甚至替换它来改变部分架构。有人正在构建一个使用systemd而非docker的kublet,而Fly.io(似乎对Kubernetes颇有微词)则编写了一个能通过其边缘基础设施部署服务的kublet。
API服务器不仅执行验证,还允许其他微服务通过Pod准入webhook插入验证链。
其他示例包括:部署控制器、副本集控制器、水平Pod自动缩放器和集群自动缩放器。这些组件既能独立运作,又能协同响应动态环境变化。操作员是管理特定应用组件的微服务,例如 Redis、RabbitMQ、PostgreSQL、Tailscale 等。
这种架构的重大优势在于使 Kubernetes 具备高度可扩展性。第三方供应商可编写定制微服务对接其平台(例如为 GCP、AWS、Azure 或 Ceph 等提供存储接口)。实施Kubernetes的企业可根据需求进行定制,无论是精简部署还是在高度监管的市场中运行。
讽刺的是,许多人通常将Kubernetes视为单体架构。虽然Kubernetes及其设计解决的领域确实复杂,但将其误解为单体架构会给使用者带来诸多困惑。
这正是亚马逊闻名的经典“两披萨团队”服务导向架构。微服务规模远小于此。在我当前团队中,微服务数量甚至略多于工程师人数。
> 在我当前团队中,微服务数量甚至略多于工程师人数。
你当然可以这么做,但这种对微服务的解读过于狭隘,与行业主流观点相悖。如我前文所述,我描述的是谷歌内部定义的微服务范式。微服务在定义上并非必须更小,但若你愿意,完全可以将其拆解得极其微小。
参考其他关于微服务的论述,你会发现它们与我的观点一致。
例如维基百科给出的二分法:“面向服务的架构可通过Web服务或微服务实现。”按此定义,所有非基于Web服务的架构都属于微服务架构。
谷歌云平台列举了若干实例:
每个微服务都是艰巨任务。正确实现购物车或客户账户功能需要整个团队协作。事实上,针对这些特定问题,已有众多企业提供SaaS解决方案。我理解你的意思是:如果团队正在开发购物车功能,可能会将其拆解为更小的服务模块。这无可厚非,但绝非微服务定义的必要条件。
Azure官方指南https://learn.microsoft.com/en-us/azure/architecture/guide/a…指出:
> 围绕业务领域构建服务模型。运用领域驱动设计(DDD)识别边界上下文并明确定义服务边界。 避免创建过度细粒度的服务 ,此类设计会增加复杂性并降低性能。
Azure另提供微服务边界确定指南,其中同样强调构建此规模微服务需全团队协作https://learn.microsoft.com/en-us/azure/architecture/microse…
我开始从组织效率而非技术层面论证。实践证明,展示决策与变更所需的大量人员和团队如何影响新功能交付周期更为有效。
尽管如此还是试试分享吧!:D
我以为微服务早已过时,正因如此这类文章才终于出现。
关键不在于微服务有多陈旧,而在于零利率政策终结后,软件开发效率提升与基础设施成本优化终于面临压力。开发者正乘着这股新浪潮前行。
这篇文章时不时会出现在这里,但值得一读:https://softwarecrisis.dev/letters/tech-is-a-pop-culture/
真想把这篇文章倒送回11年前
我认为,在“是否采用微服务”的讨论中,工程思维模式才是真正的挑战所在
我的意思是,我时常看到——甚至可能亲手将这句话当作棍棒使用——“这个组件有明确的契约,它隐含着独立性,迫使人们记住:若修改需要触及其他部分,就必须进行沟通”。现实中确实需要对软件进行充分划分,避免工程师越界操作(即因注意力不集中导致变更意外破坏其他模块)。
但在Facebook,我们只依赖单元测试。若他人破坏了你的代码,除非你有测试覆盖,否则责任在你。
当然新闻推送等模块采用微服务架构,但据我所知,fb.com网站和移动端应用的GraphQL服务默认仍基于单体架构。
事情并非如此非黑即白。
BEAM生态系统(Erlang、Elixir、Gleam等)能在单体架构内实现分布式微服务。
单体架构可通过不同部署方式满足多样化扩展需求。例如:一组Pod专司报告接口响应,另一组仅处理WebSocket连接,其余Pod承载其他接口。这些组件可独立扩展,但保持统一发布节奏。
我曾读过一篇长文对此进行过论证:当存在 M 个代码源时,可部署单元数量为 N。交付系统的职责正是实现 M -> N 的转换。M 的定义取决于工程团队的代码协作模式——无论是单仓库、多仓库还是共享库等。而N则代表运维层面的合理规模。通过让交付系统承担M→N的转换工作,即可实现M与N的解耦。可惜我已记不清该文章标题(或许网络上有人记得)。
> BEAM生态系统(Erlang、Elixir、Gleam等)能在单体架构内实现分布式微服务。
这并非新概念。任何支持模块加载的语言都能在保持单体架构运行模式的同时,提供微服务带来的组织优势(若你认为这是优势的话——实际上极少组织能真正 受益 于这种分离)。Java早在20多年前就能做到,只需将.WAR文件上传至应用服务器即可。
> Java早在20多年前就能实现,只需将.WAR文件上传至应用服务器。
Erlang近40年前就具备此能力。
它能支持运行时无中断应用升级。这在Erlang中效果极佳,因其从底层设计就为此而生。我知晓数个实际应用该特性的案例。
Erlang 似乎是种令人愉悦的语言。职业生涯中尚未有机会接触它,心中不免有些遗憾。(业余时间实在抽不出精力钻研,但它确实在我未来的计划清单上。)
不妨试试Gleam [0],号称“一天就能学会的语言”。它具备类型安全特性,支持BEAM虚拟机,可轻松调用Erlang和Elixir。编译后可生成Erlang或JavaScript代码。
[0] https://gleam.run/
看起来很棒!感谢推荐!
这正是我从未关注它的原因——人人都说它很棒,但…除了死忠粉外,没人用它做生产环境或个人项目
或许未来某天能崭露头角,但照过去的情况看…
我用Elixir做过生产环境项目(支持师生实时课堂互动的学习平台)。
WhatsApp是用Erlang实现的。
它更适合构建智能体AI平台,若开发智能体AI项目,我肯定会优先选择BEAM语言。
WhatsApp固然是经典案例,但若深入挖掘,还有大量成功实例。
在零利率政策后的现实环境中,“小团队,大成果”正是我最关注的特质。
我了解WhatsApp及其与Erlang的关系(还有RabbitMQ,每次被问起总会忘记提及…)
但它们几乎是仅有的真实案例
若提及Go语言,人们会列举Docker、Kubernetes、etcd等大型项目,以及谷歌内部应用等少数案例(Uber?)
Erlang却缺乏这种认可度,这令人担忧——毕竟它作为开源语言的诞生时间比Go更早,甚至比Python还早(尽管当时是专有语言)。
作为从未使用过它的人,我感觉它浑身写着“除非有学术兴趣,否则别费劲了”
Erlang的理念总被(拙劣地)重新发明。
因此它始终是“秘密武器”,我对此很满意。并非所有事物都需要通过流行度来验证其非凡效力。
BEAM提供的并非模块化,而是并发性。每个genserver都在运行时环境中并发运行。在Java引入演员模型之前,以及近期采用轻量级线程的Java之前,Java都无法实现这种特性。Java至今仍缺乏BEAM和OTP所提供的功能。
此外:Erlang诞生于Java之前。
当然,有人可能会辩称只要涉及ASP,VB6也能实现类似Java的功能…确实见过这样的实现:基本接口类似于Actor,但本质更像是“接收键值对作为输入,进行处理后返回键值对进入下一阶段”,再辅以必要的粘合代码来处理流程。这种粘合机制的妙处在于,引入新模块时几乎无需额外仪式。
说实话,这个设计足够精妙,以至于我每隔几年就会想用其他语言重构这个概念…
没错,关于BEAM的见解很精辟。当年微服务风靡时我们常开玩笑说BEAM早已领先一步——gen_server就是轻量级隔离进程的典范。只需为其定义回调API封装器,就能在集群中部署数百万个实例。
没错,这种隔离性提供了直到Kubernetes出现才广泛应用的容错能力。
不过为BEAM实现服务网格的部分优势会很酷——比如统一应用网络重试/断路器策略,或动态扩展gen_server。
虽非完全反驳,容我补充如下。我管理着由4名Scrum Master带领的团队,每组负责5-6名工程师。我们通过称为控制台的用户界面提供服务,这种模式对任何B2B或B2C服务商都相当熟悉。该门户的后端按功能领域拆分:计算管理服务提供处理计算资源的CRUD接口,存储服务管理存储资源的CRUD操作,网络服务负责网络交互等,所有服务共享单一(但已分片)的基础数据存储。
团队接手任务后,检出代码,运行等效于docker compose up的命令,构建功能模块。提交至Git后,代码经开发分支合并至主分支,再通过管道部署。此流程每日执行多次。若采用将所有接口整合为单一应用的大型单体架构,操作虽不困难却毫无益处——反而会产生额外负担:四个团队频繁处理相同代码,需反复执行rebase和pull操作,无法实现简单的原子性变更。每个服务都打包为容器部署到ECS Fargate上,运行在若干台EC2实例中。虽然这些实例在所有容器同时承受高负载时可能略显不足,但90%的时间都游刃有余,因此成本效益极高。
每当看到关于微服务的热议,我总想指出:若组织运作失灵,任何架构都无济于事;若组织运作良好,基本任何架构都可行。但就我所见,对于小型团队而言,采用领域驱动设计并共享持久层的“微服务”模式往往是理想选择。
> 我们有4个团队频繁修改相同代码,需要通过rebase和pull合并变更,而非推动简单的原子变更。
无论如何都需合并变更。团队间要么存在契约变更,要么不存在。若不存在契约变更,无需rebase,直接squash合并即可。若有契约,你现在就能发现变更;若无契约,等到容器在生产环境抛出错误时才发现变更就晚了。
我正在帮助一家公司摆脱遗留系统困境。与其直接要求采用微服务,不如先从面向服务架构入手——这已是巨大的进步。
对多数企业而言,服务导向架构完全足够。当你需要微服务时,才意味着真正成功——这既是用户活跃度极高的标志,也是产品取得成功的证明。
莫要操之过急。保持简单,傻瓜。
> 与其宣称需要微服务,不如先从服务导向架构起步。
我认为微服务之所以被称为“微服务”而非“服务导向架构”,主要在于它试图复兴原始的SOA理念——当时“服务导向架构”这个名称仍因与XML及WS-*标准系列的关联而蒙尘(讽刺的是,这些标准支持的交互往往仅实现该架构概念的子集,却未真正践行其设计思想)。系列标准(讽刺的是,许多系统虽支持这些标准的子集进行交互,却并未真正践行该架构风格的理念)。
面向服务的架构似乎是个相当不错的想法。
我在某家公司见过几件令人遗憾的事:他们最终交付了微服务架构的设计,却对服务接口考虑不足。举个小例子:A团队负责一个夜间运行的服务,该服务生成客户专属推荐并写入数据库;而B团队负责将这些推荐作为面向客户的应用功能展示,并直接从该数据库读取数据。这种情况很可能是因为A团队拥有数据科学家,B团队拥有该功能的应用后端工程师,双方都急于交付成果,而架构师或资深工程师却未在接口问题上坚持原则。
若A队和B队属于同一团队,这种设计尚可接受——他们可将数据库视为内部资源,要求所有访问都必须通过接口明确的服务。但若非如此,在缺乏明确接口的情况下,数据库数据模型的架构变更将难以推进:既无法将实现变更与消费者解耦,又需应对B队自身季度优先级清单的冲突。
微服务及其替代方案并非孤立的技术属性,它们同样取决于组织架构图及各团队对整体系统的职责划分。
SOA:相当不错;微服务:未必是好主意;脱离SOA的微服务:应避免。
对于不熟悉SOA的人,Steve Yegge在2011年针对谷歌平台的抨击文章[1][2]中有精彩论述,重点探讨了亚马逊转向服务导向架构的历程。
[1] https://courses.cs.washington.edu/courses/cse452/23wi/papers… [2] 对应的2011年HN讨论串https://news.ycombinator.com/item?id=3101876
哪些特征定义了“遗留系统地狱”?
我很好奇,具体的问题清单和痛点(如果——这个“如果”很大!——所有人都能达成共识的话)能更清晰地指导决策:下一代架构该采用什么形态——SOA、单体架构等等。
试试20多年的Git历史(没错,他们是从SVN迁移到Git的)。
最大的障碍在于转变人们的思维模式——从传统编程思维转向现代DevOps工作流。让他们相信这种转变值得付出努力。
能具体说明吗?这听起来像是陈旧的代码库和糟糕的编程实践。代码库的哪些问题以及你们在使用中遇到的困难,让你们认为需要重构?又是什么迹象表明微服务可能是合适的解决方案?
若言辞显得尖锐还请见谅,绝无贬低之意。在人力与技术受限的情况下,微服务/面向服务架构往往是最佳选择——我并非质疑,只是好奇。
我从未宣称微服务是万能解药,只是指出面向服务架构对传统平台而言是重大飞跃。
本讨论的核心在于微服务常被滥用在非必要场景,而我完全认同这一观点。
每当看到痴迷微服务的工程师坚称:将简单可靠的进程内函数调用改为网络跳转+序列化+重试+后退+断路器逻辑反而更快时,我总是震惊不已。我确信微服务有其适用场景,但从未亲眼见过。更多时候我看到的是工程师在复杂性沙盒里玩耍,最终交付充满漏洞的代码。这让我想起电影《点球成金》里比利·比恩的质问:“既然他是好击球手,为什么打不好球?”
我深信“专注做好一件事”——这正是UNIX哲学的精髓。
无论是精于特定功能的程序…还是简单的函数/过程——关键在于我们试图解决的问题本身。
我向来不喜欢“微服务”这个词,但我的目标始终是构建简洁的解决方案。在这个领域我不断学习新词汇。多数情况下我构建的是“微服务”,但也有少数被归类为“微服务”的方案——它们同样毫不复杂!
我更倾向称之为“分布式计算”,因为解决方案既可能是单体架构也可能是微服务架构。本质上你构建的是二者的组合体,它们通过某种形式进行通信。
我永远记得过去工作中那个收银系统:采用单体架构加数据库,数据传输到服务器时效率低下且速度缓慢。随着欧洲新门店不断增加,系统是否变得难以管理?是的。但这绝非单体架构的过错——它最初是为“良好”而设计的解决方案,如今只是力不从心罢了。
我替换的解决方案允许通过ZeroMQ将数据发送到服务器。效果很好——速度快且可靠。服务器端将每个部分拆分处理。再次强调:这既不是完美方案,也不证明“单体架构比微服务(或分布式计算)更差”——绝非如此!事实是我们的软件融合了所有这些架构!
我个人认为ZeroMQ被严重低估了。它能解决诸多难题。
但推广采用并不容易。它既非HTTP协议,也非传统队列系统。
需要大量解释、思考,最终还得开会讨论。
我在ZeroMQ中大量运用了推拉模式(Push-Pull),但也零星使用过其他模式(发布-订阅等)。
不过——我必须大力赞扬路由器-经销商模式(ROUTER-DEALER)!这种模式在发送大块数据时无需等待每条数据的响应,简直太棒了。
HTTP根本不适合这类任务。
不过——我完全理解你的感受!解释某些决策确实耗时费力。不知不觉间,我曾耗费整整四小时,有时甚至更多。
最后你问我是否该选择平庸方案…但大家都心照不宣。
(“平庸”并非准确表述。我的意思是本可选用Kafka或RabbitMQ。但这会增加额外层级,涉及基础设施部署并导致进一步延迟(当时如此))
当系统中两个组件的扩展需求存在显著差异时,就需要采用多服务架构。道理就是这么简单。这类架构常被称为微服务,但实际规模未必“微”
在我看来,这是采用微服务最荒谬的理由。
试想:应用程序中每次API调用(或函数调用)都有不同的扩展需求。应用程序中每行代码都有不同的扩展需求。无论你选择将所有功能“整体”作为单体应用扩展,还是分别扩展,这有什么区别?更进一步说,我认为整体扩展更优——当某个功能遭遇异常负载时,整体架构能提供的缓冲空间远大于分散部署。更不用说进程内/进程间通信成本远低于网络调用。
采用微服务的“正确”理由纯粹是人为因素——将复杂性拆分到单人或单团队可控范围。假设存在某种超级智慧的外星物种,它们划分微服务边界的标准可能完全不同。
此刻我确信,太多人从未以非高度Kubernetes化的方式构建软件,因此根本不知道这种可能性存在。在这个领域,开发者总觉得笔记本的32GB内存不够用,可当年登月任务用的内存才4K左右。软件行业已丧失历史与文化记忆,导致毕业生们根本不明白:如今一台五年机龄的服务器完全能处理每秒1万次连接。
许多开发者起步于零利率政策时代,当时“工程化”的常规约束(成本控制等)形同虚设,复杂架构和高昂云账单反而被视为美德,难怪会如此。
拆分职责到独立服务的核心目的,本应是降低成本。
确实存在因根本原因消耗大量资源的软件,当为独立扩展而拆分单元时反而能节省实际成本。这类软件大多并非主要处理连接数量问题。
你只关注理论而忽视成本,这属于工程能力不足。
你在说什么呢。
当人们讨论扩展需求时,关注的并非“某功能每请求需X CPU,另一功能需Y CPU”这类细节,而是判断特定端点的主要瓶颈是否存在差异(如CPU vs 内存 vs 磁盘)。这很重要,因为如果某个端点需要X个CPU而我需要扩容机器,但同个服务还有另一个端点需要Y内存——而原始服务仅需Z内存,且Y远大于Z——那么突然间你就要为CPU瓶颈端点支付大量额外费用,只因它与内存瓶颈端点共用资源。
如果所有端点只是执行不同逻辑,都访问几个Redis端点、运行几个Postgres查询并整合结果,那就把它们全部放在一起!!!
编辑:我原帖甚至用了“显著差异”来描述何时该拆分服务!!!这简直像你决定和人生中遇到的某人争论,却把矛头指向了我
我见过另一种情况是将系统中特定部分独立出来,这些部分涉及监管或合规要求,可能难以在更大系统中统一支持,例如HIPAA合规、PCI合规等。
(说明一下,我并非反对你的观点!)
说得对,我主要考虑的是工程因素,但确实还存在其他顾虑。
这种做法还有其他优势。
从运维角度看,能在补丁周期内独立更新某个离散功能非常理想。你可以说服自己用模块化单体架构也能实现,但独立服务的物理隔离能提供测试/审查/良好意愿都无法比拟的保障。
不过这同样是支持SOA架构的论据,与微服务架构的优势并无二致。
核心基础设施必须永不宕机,而某些服务则需快速迭代——为这两类组件设置不同发布周期便是另一项优势。
当然,除非应用规模极小且完全不管理服务器,否则“每个功能独立为一个服务”的做法确实过度设计。
我来此正是要表达相同观点。若你仍在争论微服务的是非对错,可能根本没正确理解问题本质。当资源需求高度均匀时,运行单一大型服务或许合理。即便需求不均,也需权衡增加复杂性的代价与过早或不必要扩展某些组件的成本。这往往是拆分流程前可接受的过渡阶段。
单体架构同样支持水平扩展:可均衡分配请求或将特定请求路由至特定实例。唯一缺点是这些实例需占用数百MB内存存储永远不会使用的端点代码——但相较微服务环境的人力成本,内存开销微不足道。
根据这些数据,确实应该这样做。但建议将数据库部署在与应用程序不同的机器上,因为实际差异可能远超几百MB。
我曾参与一个项目,其中gRPC服务器负责为另一服务插入数据库数据。
这种拆分可能是错误的,因为暴露的接口导致我们实际执行了双倍于必要的数据库调用。
其中一个存储过程需要一个魔数参数,而该参数需通过另一次数据库查询获取。
团队里有位开发试图说服我另写一个gRPC服务器来处理这个(极其简单的)查询:
“我们搞的是微服务,所以必须把所有东西都做得尽可能小。查询这个值和插入数据是两个独立职责。”
幸好我们的技术主管头脑清醒,支持了我的观点。
我推崇“金发姑娘”式服务——根据领域/资源考量灵活调整规模,通常不存在单一HTTP端点服务。
曾经,这才是微服务的本真。单体架构指公司所有软件集成于单一软件包。
我认为转折点在于FaaS的出现,人们开始将纳米服务冠以微服务之名,由此催生了诸多愚蠢决策。
我曾参与过真正的单体架构开发,那绝非愉快的经历。当其他团队的失误导致你的变更被回滚,且难以隔离两个变更的影响时,那种煎熬实在令人窒息。
承接其他几位回复者的观点:
我不想要微服务,我要的是可执行程序。内存直接共享,集成化的IDE和编译器能完整感知整个系统。
这种模式或许适用于小型项目:团队成员技艺精湛且紧密协作,系统结构清晰明确,每个人都对整体架构有足够高层次的理解,清楚哪些依赖关系健康合理。
但除非能强制要求不同组件间的访问必须通过明确定义的接口进行,否则共享内存可能导致开发者轻易在不应耦合的组件数据结构间建立直接依赖关系。这将使代码库陷入高度耦合的困境,后续演进变更将变得代价高昂甚至难以实现。
> 但除非能强制要求不同组件间的访问必须通过明确定义的接口进行,否则代码库可能最终形成高度耦合的结构,导致后续演进变更成本高昂甚至难以实现。
你描述的正是我目前在日常工作中深恶痛绝的“微服务架构”。微服务拥趸们会精确指出“那根本不算真正的微服务,而是分布式单体架构”,但我的核心观点在于:选择微服务本身并不能强制保证任何架构质量。它只是意味着,由于海伦定律的存在,你所有的错误都将被永久封存,而非作为私有/未发布的函数——后者还能通过“查找所有引用”和单元测试轻松重构。
> 通过某种明确定义的接口
所有编译型语言都具备“接口”概念,若坚持独立构建,甚至能加载编译后的模块/程序集。
编译器对接口合规性的强制执行,远比通过网络访问无类型JSON接口更可靠。
大型团队采用单体架构成功开发视频游戏的案例比比皆是,Linux和PostgreSQL等开源巨头亦是如此。
我痴迷于将所有功能——包括HTML模板、JavaScript和CSS——编译成单一(尽管庞大)Go语言二进制文件的构想。
虽然尚未实践,
但这个理念令我着迷。
Deno Compile已能实现此功能
https://deno.com/blog/deno-compile-executable-programs
但它基于JavaScript和TypeScript,而我尚未掌握这些语言。
看来终究得学JavaScript了。
这正是我副业项目的实践!为我和伴侣打造的智能相框套装。单个可执行文件实现:
– 上传API
– 上传界面
– 相框API
– 相框界面
界面采用solid-js和solid-start进行静态生成,通过gin框架提供服务。
这真的很有趣。
当年写Scala时我超爱uberjars。虽然不太怀念JVM,但确实怀念那种只需上传单一可执行文件就能运行、无需关注主机环境的日子。
这正是Docker如今承担的角色——所有运行所需都封装在单一镜像中。
没错,但根据我的经验,构建Docker镜像通常比上传单个JAR文件更耗时且更笨重。
更耗资源?确实。更慢?性能应该相当。除非你在非Linux主机上运行,否则Docker不会造成性能损失。
唯一能想到JVM可能更快的场景是多租户环境。这种情况下,JVM通过垃圾回收机制比运行多个JVM更高效。
我并非指应用性能下降(实际上可调优项增多反而可能提升性能),而是整体构建+上传流程明显变慢。记得2016年重建并部署uberjar只需不到1分钟,而如今同等复杂度的应用耗时却在3-15分钟之间。当然,这涉及不同公司、语言和环境,存在诸多潜在差异。
没错,这与Docker无关。
Uberjar(通常)会提取所有jar依赖中的类文件并合并为单一jar,整个过程都涉及gzip压缩。
容器层本质上只是保存文件系统修改记录。若使用Jib等工具构建镜像,实际部署包体积应远小于超级JAR。因为Jib会将依赖项与应用程序JAR分别存放于不同层级。按常规工作模式,通常仅传输应用程序代码,依赖项仅在变更时或基础镜像更新时才需传输。
好棒的昵称!
有趣的是,我们在这类话题上已在HN讨论至少十年了。
我不想要微服务,我真正想要的是自包含的WebAssembly模块!
这种方案相较容器化的性能取舍如何?我听说过运行WASM的操作系统(https://github.com/JonasKruckenberg/k23)。
这高度取决于所使用的WASM运行时。近年(过去几年)尚未见到可靠的基准测试。不过据我所知,wasmer团队正在筹备相关测试并尝试实现结果自动化。
毫不夸张地说
微服务是零利率政策时代的产物。像Monzo这样的机构甚至宣称每位工程师负责3个微服务。
三层架构在多数工作负载中屡次证明其稳健性。
每个披萨大小团队负责1个微服务似乎效果相当不错。
Put it into a monorepo so the other teams have visibility in what is going on and can create PRs if needed.
Uh? You eat less than a pizza per person?
To be fair pizzas are quite easy to scale from small kid sizes up to enough for several persons.
But it is a bit sad that the poster apparently never bought a pizza just for themselves.
It's a reference to Amazon's statement that teams should never grow larger than a team that you can feed with 2 (large) pizza's.
The optimum is probably closer to 1 than to 2.
8x engineer
Certainly no more than three tiers.
"Traditional" three-tier, where you have a web server talking to an application server talking to a database server, seems like overkill; I'd get rid of the separate application tier.
If your tiers are browser, web API server, database: then three tiers still makes sense.
We've removed/merged most of the unnecessary services. The ones left have operational needs to stay separate.
The current hell is x years of undisciplined (in terms of perf and cost) new ORM code being deployed (SQLAlchemy). We do an insane number of read queries per second relative to our usage.
I honestly think the newish devs we have hired don't understand SQL at all. They seem to think of it as some arcane low level thing people used in the 80s/90s.
in my opinion "you need microservices" peaked around 2018-2019 … does nowadays someone think that, apart from when you reach certain limits and specific contexts, they are a good idea?
Half of the jobs I'm applying to have microservices in the description, much more often than, say, REST or Boot, so somebody definitely thinks they're a general solution to something.
I went through some interviews where they put microservices in the job description but when asked it turned out to be a kind of monolith for core + a set of other services for other stuff (authentication, logging, analytics).
Microservices is an excellent generator for developer busywork and increased headcount. Busywork benefits the developers, increased headcount benefits their manager, and so on.
There's one thing I've learned about microservices. If you've ever gone down the path of making them, failing and making them again until they all worked as they should with the desired 9's of uptime, then you'll only want to make them if it's really the right thing to make. It's not worth the effort otherwise.
So no I don't want microservices (again), but sometimes it's still the right thing.
I feel like this has been beaten to death and this article isn't saying much new. As usual the answer is somewhere in the middle (what the article calls "miniservices"). Ultimately
1. Full-on microservices, i.e. one independent lambda per request type, is a good idea pretty much never. It's a meme that caught on because a few engineers at Netflix did it as a joke that nobody else was in on
2. Full-on monolith, i.e. every developer contributes to the same application code that gets deployed, does work, but you do eventually reach a breaking point as either the code ages and/or the team scales. The difficulty of upgrading core libraries like your ORM, monitoring/alerting, pandas/numpy, etc, or infrastructure like your Java or Python runtime, grows superlinearly with the amount of code, and everything being in one deployed artifact makes partial upgrades either extremely tricky or impossible depending on the language. On the operational and managerial side, deployments and ownership (i.e. "bug happened, who's responsible for fixing?") eventually get way too complex as your organization scales. These are solvable problems though, so it's the best approach if you have a less experienced team.
3. If you're implementing any sort of SoA without having done it before — you will fuck it up. Maybe I'm just speaking as a cynical veteran now, but IMO lots of orgs have keen but relatively junior staff leading the charge for services and kubernetes and whatnot (for mostly selfish resume-driven development purposes, but that's a separate topic) and end up making critical mistakes. Usually some combination of: multiple services using a shared database; not thinking about API versioning; not properly separating the domains; using shared libraries that end up requiring synchronized upgrades.
There's a lot of service-oriented footguns that are much harder to unwind than mistakes made in a monolithic app, but it's really hard to beat SoA done well with respect to maintainability and operations, in my opinion.
我认为在所有服务中共享全局数据库(而非服务内部数据库)的微服务架构具有显著价值,但对于为不同服务单独部署核心事务数据库的做法,我难以认同其价值——除非/直到组织内部两个独立部门几乎成为两家独立公司,无法作为单一组织/企业运作。这种做法将导致数据完整性丧失、联接能力受限、系统状态不统一等问题。
这种做法唯一合理的场景是:不同服务的数据访问模式在规模和频率上差异巨大,导致资源竞争点不同,需要针对性优化。但即便如此, 我的疑问是:服务内部是否真需要同类数据库的独立实例?抑或需要全局副本/新型数据库实例(例如当Postgres运行至需高效处理大规模列式数据的OLAP场景时,可考虑采用Clickhouse)。
达到这种规模时,基于单元架构[1]的构想才显合理——但即便如此,本质上仍是在构建多维分片式的全局持久化存储,每个单元仅负责路由空间的单一切片且功能隔离。这让我质疑状态绑定服务的大规模微服务价值,目前也难以想到合适的应用场景。
[1] https://docs.aws.amazon.com/wellarchitected/latest/reducing-…
> 我认为创建微服务时,采用跨所有服务的全局数据库(而非服务内部数据库)具有很大价值
但这会引发模式演进问题。以最简单的例子说明:假设存在一个User表,多个微服务访问该表。现在你需要添加“IsDeleted”列实现软删除功能,该如何操作?首先需在数据库中实际添加该列,随后必须逐个更新所有查询该表的服务,确保它们能过滤出IsDeleted=True的记录,部署所有这些服务后才能真正启用该列。若必须以这种步调一致的方式更新服务,你实际上构建的是分布式单体架构——既保留了微服务的所有复杂性,又丧失了所有优势。
正确的服务导向处理方式是:由单一服务掌控用户表,并暴露
GetUsers接口。如此只需更新数据库及其关联服务即可支持IsDeleted字段。基于API稳定性保障(优质SOA的另一关键特性),其他服务调用该接口时仍能获取未删除用户,无需自行更新逻辑。> 你将失去数据完整性、关联能力、统一一致的系统状态等特性。
确实会失去这些特性!这正是权衡取舍之一,也说明理解业务领域对做好SoA至关重要。对于数据完整性要求严格的业务子集,所有数据 应当 集中存储于单一数据库并由单一服务管控。但对多数业务领域而言,大量功能并不存在严格的完整性要求。以一个具体但略微简化的例子说明:我从事物联网时间序列数据工作,平台某项功能是通过机器学习算法基于历史趋势预测未来值。预测计算及其结果存储在独立服务中,结果通过“外键”关联回主数据库中的设备ID。那么,若该设备从主数据库中被删除会发生什么?预测服务数据库中将产生大量孤立记录。但这究竟有多严重?我们从未通过预测记录中的设备ID反向追溯设备信息,查询始终是“请提供设备ID 123的预测值”这类模式。因此实际影响仅是数据库膨胀,若真有顾虑,可通过定期孤立记录检查流程解决。
若你习惯“所有数据通过外键关联存储于单一关系型数据库”的策略,这确实需要思维转变。但我见过许多公司(包括AWS)成功采用这种方案。
我理解你关于软删除示例的观点,但这更像是模块分离不佳+关系型查询抽象/复用问题,而非共享数据库的缺陷。无论是服务、模块还是库,抽象边界渗漏终将引发问题。我认同你关于独立服务分版本管理的观点——这确实能简化特定迁移操作,但代价是增加系统复杂度并延长双系统并行维护周期。
我通常观察到共享状态微服务与隔离状态微服务的核心差异在于:前者引入了网络调用(尽管OLTP状态由单一主节点管理),而后者则面临多存储同步与冲突解决的难题。这些权衡取舍令人痛苦,若无充分理由(虽然我极少见到,但不能断言绝无可能)来牺牲这些特性,其合理性甚至值得质疑。
关于你的物联网案例——这确实是值得告别舒适区RDBMS的场景。该访问模式以读写为主,涉及时间序列数据,采用同质化行布局且更新频率极低,正是Clickhouse这类列式存储的绝佳用武之地。我在$MYCORP公司迟迟未采用该方案,正是出于前述对失去RDBMS便利性的顾虑(况且我们的数据量尚未达到必须垂直扩展的规模),但若数据量激增,情况或许截然不同。
综合来看,我认为微服务真正适合特定场景(即使采用共享状态/分布式单体架构也能创造价值)的情况仅有以下几种:
[共享状态] 多语言实现——这是我在其他机构最常遇到的典型场景;通过构建功能上等同于分布式单体的架构,能在几乎零维护成本的情况下同时使用多个技术生态。由于我常在Python生态中工作(可随时切换Cython、Numba等加速方案,且该生态本身规模庞大),这种需求并不常见。但在前公司,为利用Java生态而创建服务,相较于固守原有生态,对组织而言是重大胜利。除此之外,前端后端独立部署可能是最简单实用的实现方式——我在几乎所有项目中都采用过这种模式(毕竟主要服务于交付单页应用的团队)。
[共享状态] 软件开发生命周期速度——随着单体应用的增长,检出大型仓库、配置环境运行测试的过程变得极其繁重,而持续集成中这些操作的重复执行更是雪上加霜。当仅需针对代码库子集执行构建流程和测试套件时,整体CI耗时可实现数量级的提升——根据经验,这往往是团队交付代码速度的瓶颈所在。
[多存储] 大规模专用访问模式——某些工作负载确实难以通过关系型数据库实现高效简洁的处理,除非承担持续的维护负担。我能想到的两个典型场景是大型OLAP工作负载和搜索/向量数据库工作负载; 当Postgres全文检索无法胜任时,使用ElasticSearch这类工具实属必然;而面对大规模时序查询时,若采用Postgres成本将激增十倍且系统脆弱,此时使用Clickhouse等工具或许别无选择。即便如此,这些场景仍更接近“多单例存储”而非“单服务单存储”模式
[多存储模式] 独立服务对应独立收入线——这或许是微服务从第一性原理层面最理想的形态。该服务能否作为独立产品与收入线存在于代码库之外?是否由独立业务部门实际销售并运营?若符合上述条件,该服务本质上应成为企业内部独立的“公司”,拥有自主权和独立性,可按自身需求消费上游依赖(并向下游暴露依赖)。在AWS任职期间,这种模式具有压倒性的合理性——亚马逊众多内部构建的优质产品同时面向外部销售的事实,让我对此深有共鸣。
5 [多仓库] 机制用于强化组织分工中的规范性与责任归属——在我看来,这是最值得质疑却又最常见的变体。微服务依然充满吸引力,能为雄心勃勃的工程师创造高曝光度的职业晋升项目履历,即便这可能损害其所在公司的整体利益。微服务可作为官僚机制,将代码库某部分的责任与所有权强加给特定团队,以避免公地悲剧导致的代码不可读性——但最终我常发现,转向微服务并未更有效地解决导致公地悲剧的根本力量与挑战,反而增加了解决成本。
回复1:我认同马特·兰尼的观点,他认为微服务本质上是一种技术债务——它让你能更快、更独立地部署,代价是整体代码库变得更复杂。
这明确了微服务适用的场景:当企业处于高速增长期,部署瓶颈远大于代码瓶颈时。DoorDash在疫情期间采用此模式合情合理,但这实属特殊情况。
我不要微服务!
我想要的是面向巨型服务的轻量级基础设施。需要处理用户认证与机器间认证(可能还包括授权)。
我不需要常规的K8s虚拟网络,只需服务内部自带的易用模块。
所有组件都应能在本地docker-compose容器中快速部署。
> 我想要的是为宏服务构建轻量级基础设施。需要处理用户认证和机器间认证(可能还包括授权)。
> 不要常规的K8s虚拟网络,只需服务内部易用的模块即可。
若配备专职团队(或至少一名工程师),且确实需要蓝绿部署、弹性扩展等高级功能,K8s才是合理选择。正确配置后,它确实是相当优质的平台。
若无需这些功能,Docker(或更优选的Podman)才是正确方向。如今仅凭VPS或独立服务器就能实现相当程度的部署。当你突破现有服务器(合理范围内)的性能瓶颈时,很可能已具备资金实力部署“专业级”基础设施。
我多次尝试使用K8s却始终无法驾驭。它作为部署平台尚可,但本地开发环境中实在难以承受其复杂性。
我们本地开发采用Docker/Podman配合docker-compose,几秒就能启动完整技术栈。既能对任意组件附加调试器,也能将其从Docker容器中提取直接在IDE运行。甚至还可选装本地Uptrace实现OTEL可观测性测试。
问题在于部署环境与开发环境迥异,导致我必须维护两套服务描述。若能统一管理就再好不过,可惜至今未见解决方案…
除非你拥有开发集群并能将特定Pod流量路由至本地工作站,否则我绝不会在本地开发中使用K8s。
本地开发用Docker Compose完全够用。若K8s环境复杂到必须本地测试,请立即停止这种做法。
Tilt?Skaffold?配置虽非免费,但本地K8集群若能实现接近生产环境的调试功能,实际使用中会相当便利。
我试过 Tilt,但依然过于复杂。例如我们有个基于 Python 的计算机视觉服务模型。在 macOS 开发时无法在容器内使用 GPU,因此必须在主机本地运行。
当前配置下这很简单,但用 Tilt 基本无法实现。
深有同感。虽然我们用Nomad而非K8s作为集群控制平面,但本地开发者仍受限于docker-compose,导致本地环境与生产环境需配置两种不同方案。
除非需要横向扩展或集群功能,Compose + Terraform已足够满足需求。
Compose能实现真正的多层应用容器化与不可变性。结合Terraform等基础设施即代码工具抽象IT环境后,仅需一条命令即可在本地、云端或客户站点部署应用。
集群需求可选用 Incus,而 Kubernetes 则适用于超快速扩展(
<mn)、大型集群海量部署、云端卸载及微服务场景。绝大多数场景根本无需 Kubernetes 的复杂性,其投资回报率(ROI)在多数应用中并不存在。
我不想要也不需要微服务。我真正希望的是人们别再把TCP往返塞进本该在正常世界里简单函数调用的流程里。我不愿为了搞定什么“宠物版Uber”之类的垃圾项目来付房租,非得先修完研究生级别的CAP定理课程才行。我敢保证,你几乎肯定不存在需要分布式系统解决的扩展问题。我的职业生涯平平无奇,但每次有人把Kubernetes这种方枘硬塞进服务器圆凿时,结果总是灾难现场。这类系统运行缓慢、成本高昂、逻辑复杂,对处理几百到几千次连接/秒(平均值,别@我讨论突发流量,我懂原理)的大多数人而言纯属多余。
再过几天,就会出现长篇大论抱怨软件又慢又烂又糟糕,却没人能理清其中的因果关系。软件之所以糟糕,是因为我们的构建方式本身就糟糕透顶。我有幸协助另一支团队维护他们那庞大的Kubernetes怪兽系统——当请求量达到每秒两位数时,整个系统就彻底崩溃了,简直是一场错误的闹剧。本该只是个带HTML模板和数据库的Rails或Django应用,却被拆分成三四个Kubernetes Pod,用gRPC进行低效且多余的通信。系统崩溃简直成了家常便饭——这完全是Kubernetes不必要的复杂性及其配套繁文缛节造成的直接后果。
在此重申:Kubernetes所做之事,操作系统皆能胜任,只是效率更高罢了。网络管理?操作系统已然具备。调度机制?操作系统早已实现。资源分配与沙箱隔离?只要操作系统足够优秀,完全能够胜任。访问控制?当然没问题。
我敢断言:95%的情况下,你根本不需要Kubernetes。至于剩余5%的情况,请深思:你是否真面临分布式系统能解决的技术难题(且能接受其引发的其他问题)?我经历过五六个硬塞Kubernetes的项目,可以断言——这根本得不偿失。
> 我不想被迫去修研究生级别的CAP定理课程
若真有人这么做反而是福,至少能避免构建无用的分布式系统。
> 滥用gRPC进行低效且多余的通信
至少你还有福气用gRPC,不必手动编写JSON序列化/反序列化器。
> Kubernetes 做的任何事,你的操作系统都能做到
若需跨多台机器进行编排,Kubernetes 确实有用。当然这前提是你真需要多台机器。若你用的是性能不足的云虚拟机(其中三分之一内存被 K8s 本身占用),不如直接租用一台更大容量的虚拟机,跳过 K8s。
我不会说Kubernetes在调度、访问控制等方面特别出色,但主流操作系统也并非完美。通用操作系统能满足众多不同用户群体的基本需求,却很少能让任何单一群体完全满意。
> 你的操作系统能做到
哪个操作系统?
任何理智的操作系统。
哪些才算理智?
微服务中唯一值得保留的是数据库表维护规范。
大型共享数据库表曾是我历任工作中最棘手的问题,修复过程极其耗费人力。
根据我的经验,软件中所有优秀特性都源于良好的数据建模。
这也让我逐渐意识到:学习计算机科学基础知识终究价值非凡。
我指的并非深奥理论,只是学位课程前两年的基础内容。
随着时间推移你会逐渐领悟:几十年前的先驱者早已洞悉这些道理,而软件工程师的本质工作,就是通过不断尝试“更优解”的过程——实践发现并非更优,却能察觉被强化或被违背的基础原理,进而提炼出更简洁的模型。
我认为微服务兴起与单体架构回潮的历程正是如此:将微服务倡导的部分核心理念带回单体领域,同时摒弃所有无益的复杂性。
我早年就领悟了这个道理,结果成了那个在别人发布功能、获得晋升时,负责收拾残局的人。
我认为当多组应用逻辑需要访问相同数据时,它们与数据库之间应存在内部API来规范访问行为。
只允许客户端执行存储过程?
这确实是可行方案,前提是你的业务场景支持将该逻辑封装在存储过程中。
数据库本质是伪装的全局变量。
呃,数据库拆分在我看来是最棘手的问题,也是我认为微服务架构中最应优先消除的弊端。微服务的大部分问题源于试图按团队结构/服务领域分割数据模型,而非遵循真正的应用/底层业务领域。这并非否定多数据库的必要性,而是随意按服务边界分割数据库的概念本身,正是摩擦/阻抗失配/开销的巨大根源。
我其实更倾向于接近完整的微服务架构模型,只要允许所有组件共享数据库(可能通过共享API层实现)。
大型组织采用微服务的原因:让团队专注于明确的问题领域
小型组织采用微服务的原因:让某些愚蠢操作几乎在物理层面无法实现
在一次重大网站重构中,我的某位初级同事提议重建单体式可重入网站…结果每秒事务处理量轻松翻三倍,响应时间减半。
我震惊了…这家伙总能想出这种点子。谢谢你,Matt。
我发现了微服务的另一项优势——AI能理解它们且注重上下文。单体应用会混淆AI,而微服务能让AI发挥更高效能。
人工智能如何影响这一领域是个有趣的问题。如果它能扩大单个工程师的工作范围,且微服务规模的主要驱动因素是康威定律,那么理论上微服务应该变得“更胖”。
但我与你观点相反:我发现人工智能需要尽可能多的上下文信息,这意味着它更擅长理解单体架构(或更胖的架构)。至少在代理式方法中,当它能访问整个Git树/源代码库时表现优异。而当需要跨源代码库进行变更时,系统往往会频繁崩溃。
这恰恰是单体架构的优势所在。
我们见证了内核从单体到微服务再到混合架构的演变。
而如今,SAAS终于迈向了最终形态——混合/微服务架构
我认为小团队喊出“该做微服务了”时,多数情况下其实想表达的是“该尝试面向服务的架构了”。尤其采用单仓库架构时,如何整合同类模块的决策已成常规流程。
例如我在的小公司有条数据处理管道,其中包含大量人工干预环节。单体架构虽可行,但对小型公司而言云成本是关键考量——单体架构无论流量大小都会导致无服务器环境加载缓慢或持续节点开销。我们的多数处理步骤是自动化且短暂的,所有客户的数据流经系统时都像波形,其平均质心大多围绕特定步骤旋转。服务导向架构让我们能够:
– 将步骤拆分为小型“应用”,通过无服务器工作进程按需运行
– 通过单一“数据服务”(本质上是整洁地组织所有数据流)避免因并发连接过多导致数据库崩溃的扩展问题
– 确保数据访问(对核心业务对象提取信息的读写操作)以统一方式进行,避免出现混乱的API版本问题
– 在人工干预环节,数据会在作业队列中的CRUD应用以通知形式暂停,由数据分析师手动介入处理。
单体架构与这种固有的“流水线”模式存在阻抗失配,无论教条如何宣扬,单体架构确实可能处理类似系统且网络流量较少。
有人可能认为数据服务本身就是微服务——它作为单一服务满足特定用例,并通过API封装数据库访问。对于小型企业对此的担忧,我会回应:“猜怎么着?它在我们这里运行得极其出色。架构就是架构:优缺点终将显现,只需审慎评估并构建有效方案。”
我不想要也不需要微服务。
我只需要服务。
另一个问题是真正懂得设计微服务架构的人少之又少。我合作过六支自称在构建微服务团队,但实际系统不过是庞大的分布式单体架构。这些团队多由老旧代码库出身的开发者组成,他们虽认同微服务理念,却无法摆脱旧有设计模式。结果只是把所有功能拆分后用网络调用包裹——简直让我抓狂。
不
通常不需要
微服务的另一典型用例——当你不得不调整单体架构的计算规模来适配新功能时。
曾有架构师对采用微服务方案大加挞伐,直到被告知该功能(运行CLIP模型)需要为每个任务实例配备GPU时,才不得不勉强让步。
我认为微服务存在的问题在于,现实世界中的许多问题往往缺乏理想中的清晰领域边界。当程序的每个部分都需要不时调用其他部分的信息时,将它们拆分成多个服务就越发缺乏合理性。
这并非意味着拆分永远没有意义,而是“微服务”的定义存在差异——有些场景下服务领域可清晰分离,有些则不然(或拆分毫无价值)。
将某物转化为服务,如同将其拆解为模块或独立函数。其优劣取决于具体情境。
天哪,这简直是亵渎!他们接下来还要贬低什么?面向对象设计模式吗?
/s